Authenticate with Private Key JWT using Amazon Bedrock AgentCore Identity
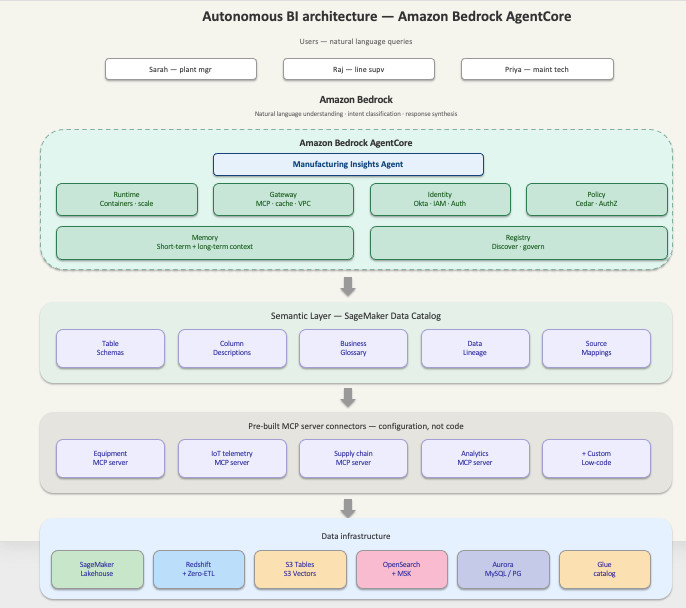
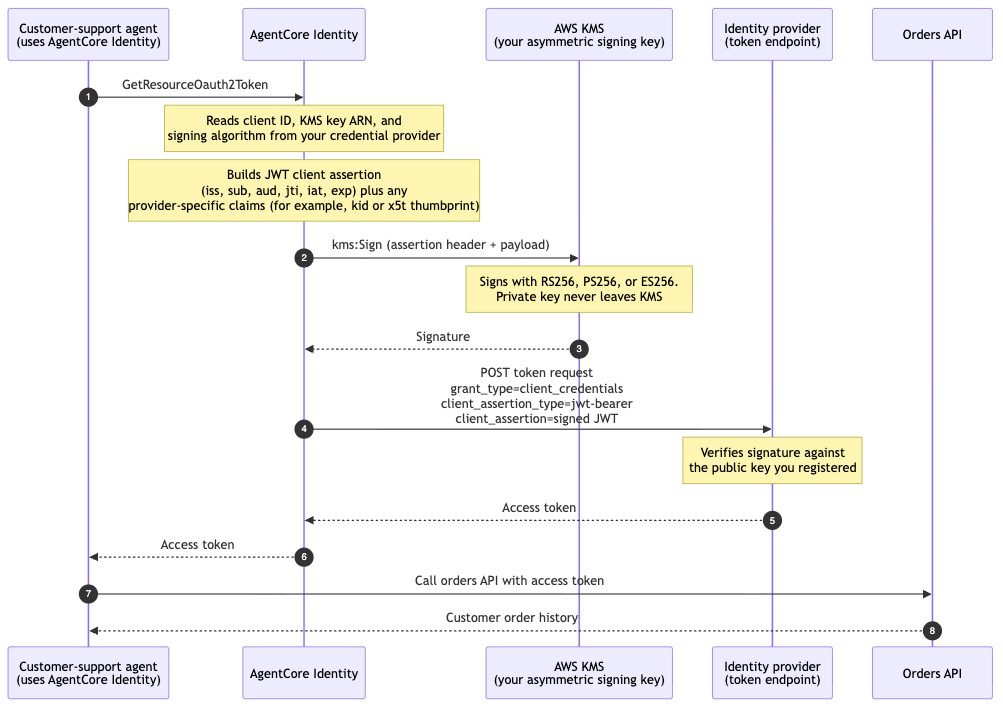
Amazon Bedrock AgentCore Identity now supports Private Key JWT client authentication for agents. With Private Key JWT client authentication, your agents can authenticate to a downstream identity provider’s token endpoint using a signed JSON Web Token (JWT) client assertion instead of a shared OAuth 2.0 client secret. You can register a public key with your […]
Authenticate with Private Key JWT using Amazon Bedrock AgentCore Identity Read More »