
A mirage in the desert looks like water from a distance and can fool even experienced travelers into chasing something that isn’t there.
SEO research can be the same.
It looks like science, sounds legitimate, and can trick even seasoned marketers into believing they’ve found something real.
Daniel Kahneman once said people would rather use a map of the Pyrenees while lost in the Alps than have no map at all.
In SEO, we take it further: we use a map of the Pyrenees, call it the Alps, and then confidently teach others our “navigation techniques.”
Worse still, most of us rarely question the authorities presenting these maps.
As Albert Einstein said, “Blind obedience to authority is the greatest enemy of the truth.”
It’s time to stop chasing mirages and start demanding better maps.
This article shows:
- How unscientific SEO research misleads us.
- Why we keep falling for it.
- What we can do to change that.
Spoiler: I’ll also share a prompt I created to quickly spot pseudoscientific SEO studies – so you can avoid bad decisions and wasted time.
The problems with unscientific SEO research
Real research should map the terrain and either validate or falsify your techniques.
It should show:
- Which routes lead to the summit and which end in deadly falls.
- What gear will actually hold under pressure.
- Where the solid handholds are – versus the loose rock that crumbles when you need it most.
Bad research sabotages all of that. Instead of standing on solid ground, you’re balancing on a shaky foundation.
Take one common example: “We GEO’d our clients to X% more traffic from ChatGPT.”
These studies often skip a critical factor – ChatGPT’s own natural growth.
Between September 2024 and July 2025, chatgpt.com’s traffic jumped from roughly 3 billion visits to 5.5 billion – an 83% increase.
That growth alone could explain the numbers.
Yet these findings are repackaged into sensational headlines that flood social media, boosted by authoritative accounts with massive followings.
Most of these studies fail the basics.
They lack replicability and can’t be generalized.
Yet they are presented as if they are the definitive map for navigating the foggy AI mountain we’re climbing.
Let’s look at some examples of dubious SEO research.
AI Overview overlap studies
AI Overview overlap studies try to explain how much influence traditional SEO rankings have on appearing inside AI Overviews – often considered the new peak in organic search.
Since its original inception as Search Generative Experience (SGE), dozens of these overlap studies have emerged.
I’ve read through all of them – so you don’t have to – and pulled together my own non-scientific meta study.
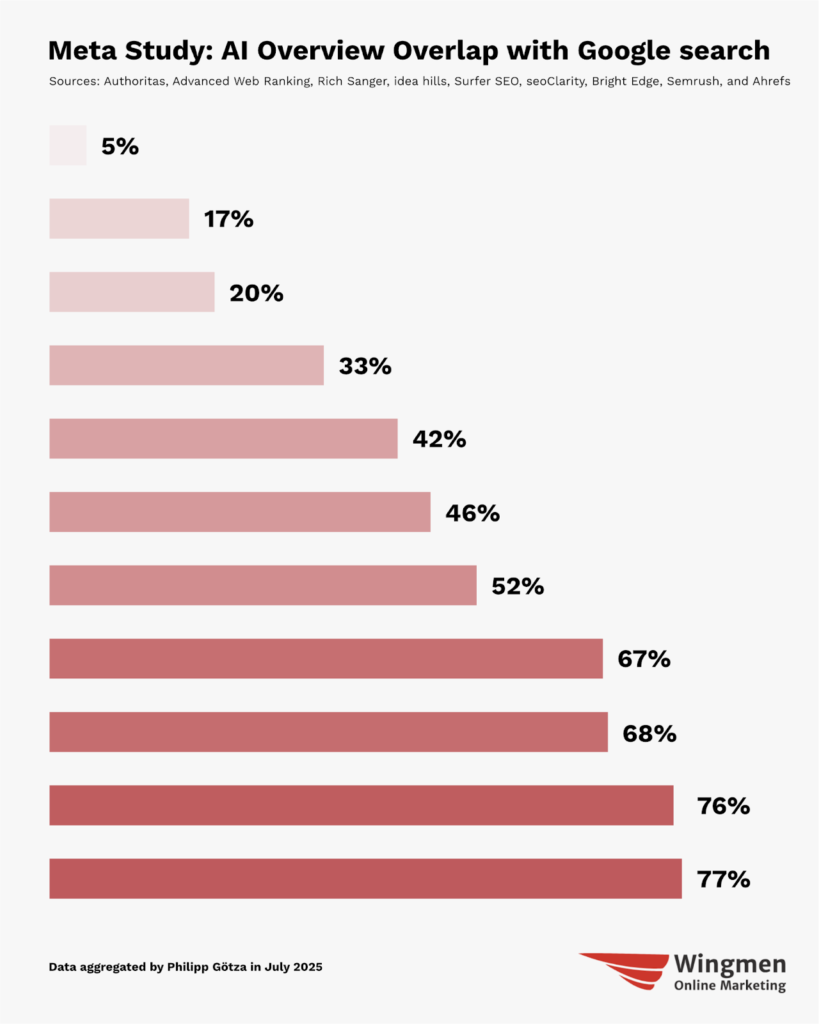
My meta study: AI Overviews vs. search overlap
I went back to early 2024, reviewed every study I could find, and narrowed them down to 11 that met three basic criteria:
- Comparison of URLs, not domains.
- Measure the overlap of the organic Top 10 with the AI Overviews URLs.
- Based on all URLs in the Top 10, not just 1.
The end result (sorted by overlap in %):

- Overlap ranged from 5-77%
- Average: 45.84%
- Median: 46.40%
These huge discrepancies come down to a few factors:
- Different numbers of keywords.
- Different keyword sets in general.
- Different time frames.
- Likely different keyword types.
In summary:
- Most studies focused on the U.S. market.
- Only one provided a dataset for potential peer review.
- Just two included more than 100,000 keywords.
- And none explained in detail how the keywords were chosen.
There are only two noteworthy patterns across the studies:
- Over time, inclusion in the organic Top 10 seems to make it more likely to rank in AI Overviews.
In other words, Google now seems to rely more heavily on Top 10 results for AI Overview content than it did in the early days.

If we exclude these studies (marked in the graph above) that didn’t disclose the number of keywords, we get this graph:
- Ranking in the Top 10 correlates with being more likely to also rank in an AI Overviews.
That’s it. But even then, there are several reasons why these studies are generally flawed.
- None of the studies uses a keyword set big enough: The results cannot be generalized, like mapping one cliff face and claiming it applies to the entire mountain range.
- AI is always changing – and always has been: The insights become outdated quickly, like GPS directions to a road that no longer exists.
- It’s not always clear what was measured: Some reports are promoted with obscure marketing material, and you wouldn’t understand them without the additional context – like a gear review that never mentions what type of rock it was tested on.
- Too much focus on averages – and averages are dangerous: For one keyword type or niche, the overlap might be low. For others, it might be high. The average is in the middle. It’s like a bridge built for average traffic – handles normal loads fine, but collapses when the heavy trucks come.
- Ignore query fan-out in the analysis: These studies give directions for where to go – too bad they’re driving a car while we’re in a boat. All major AI chatbots use query fan-out, yet none of the studies accounted for it.
This isn’t new knowledge. Google filed a patent for generative engine summaries in March 2023, stating that they also use search result documents (SRDs) that are:
- Related-query-responsive.
- Recent-query-responsive.
- Implied-query-responsive.

Google may not have marketed this until May 2025, but it’s been in plain sight for over two years.
The real overlap of AI Overviews with Google Search depends on the overlap of all queries used, including synthetic queries.
If you can’t measure that, at least mention it as part of your limitations going forward.
Here are three more examples of recent SEO research that I find questionable.
Profound’s ‘The Surprising Gap Between ChatGPT and Google’
Marketed as “wow, only 8-12% overlap between ChatGPT and Google Search Top 10 results,” this claim is actually based on just two queries repeated a few hundred times.
I seriously doubt the data provider considered this high-quality research.
Yet, despite its flaws, it’s been widely shared by creators.

German researchers’ study, ‘Is Google Getting Worse?,’ and multiple surveys on the same question from Statista, The Verge, and Wallethub
I covered these in my article, “Is Google really getting worse? (Actually, it’s complicated).”
In short, the study has been frequently misquoted.
The surveys:
- Contradict one another.
- Often use suggestive framing.
- Rely on what people say rather than what they actually do.
Adobe’s ‘How ChatGPT is changing the way we search’
A survey with only 1,000 people participating, 200 of them being marketers and small business owners – all of them using ChatGPT.
Yet, they promote the survey, stating that “77% of people in the U.S. use ChatGPT as a search engine.”
Why do we fall victim to these traps?
Not all SEO research is unscientific for the same reasons. I see four main causes.
Ignorance
Ignorance is like darkness.
At nighttime, it’s natural to have an impoverished sight.
It means “I don’t know better (yet).”
You are currently missing the capability and knowledge to conduct scientific research. It’s more or less neutral.
Stupidity
This is when you are literally incapable, therefore also neutral. You just can’t.
Few people are intellectually capable of working in a position to conduct research and then fail to do so.
Amathia (voluntary stupidity)
Worse than both is when the lights are on and you still decide not to see. Then you don’t lack knowledge, but deny it.
This is described as “Amathia” in Greek. You could know better, but actively seek out not to.

While all forms are dangerous, Amathia is the most dangerous.
Amathia resists correction, insists it is good, and actively misleads others.
Biases, emotions, hidden agendas, and incentives
You want to be right and can’t see clearly, or openly try to deceive others.
You don’t have to lie to not tell the truth. You can deceive yourself just as well as you can deceive others.
The best way to convince others of something is if you actually believe it yourself. We are masters at self-deception.
Few promote products/services they don’t believe in themselves.
You just don’t realize the tricks a paycheck plays on your perception of reality.
Reasons why we fall for bad research in SEO
We have the ability to open our minds more than ever before.
Yet, we decide to shrink ourselves down.
This is encouraged in part because of smartphones and social media, both induced by big tech companies, which are also responsible for the greatest theft of mankind (you could call it Grand Theft AI or GTAI).
In a 2017 interview, Facebook’s founding president Sean Parker said:
- “The thought process that went into building these applications, Facebook being the first of them, … was all about: ‘How do we consume as much of your time and conscious attention as possible?’ And that means that we need to sort of give you a little dopamine hit every once in a while. […] It’s a social-validation feedback loop … exactly the kind of thing that a hacker like myself would come up with, because you’re exploiting a vulnerability in human psychology.”
They don’t care what kind of engagement they get. Fake news that polarizes? Great, give it a boost.
Most people are stuck in this hamster wheel of being bombarded with crap all day.
The only missing piece? A middleman that amplifies. Those are content creators, publishers, news outlets, etc.
Now we have a loop.
- Platforms where research providers publish questionable studies.
- Amplifiers seeking engagement for personal gain.
- Consumers overwhelmed by a flood of information are all flooded with data.

We are stuck in social media echo chambers.
We want simple answers, and we are mostly driven by our emotions.
And social media plays into all of that.
How to fix all of this
As outlined throughout, we have three points that need fixing.
- Conducting the research.
- Reporting on the research.
- Consuming the research.
Conducting SEO research with scientific rigor
Philosopher Karl Popper said that what scientists do is to try and prove they were wrong in what they do or believe.
Most of us move the other way, trying to prove we’re right. This is a mindset problem.
Research is more convincing when you try to prove yourself wrong.
Think steelmanning > strawmanning.
Ask yourself if the opposite of what you believe could also be true, and seek out data and arguments.
You sometimes also have to accept the fact that you can be wrong or not have an answer.
A few other things that would improve most SEO research:
- Peer reviews: Provide the dataset you used and let others verify your findings. That automatically increases the believability of your work.
- Observable behavior: Focus less on what is said and more on what you can see. What people say is almost never what they truly feel, believe, or do.
- Continuous observation: Search quality and AI vs. search overlap are constantly changing, so they should also be observed and studied continuously.
- Rock-solid study design: Read a good book on how to do scientific research. (Consider the classic, “The Craft of Research.”) Implement aspects like having test and control groups, randomization, acknowledging limitations, etc.
I know that we can do better.
Reporting more accurately on SEO research – and news in general
Controversial and questionable studies gain traction through attention and a lack of critical thinking.
Responsibility lies not just with the “researchers” but also with those who amplify their work.
What might help bring more balance to the conversation?
- Avoid sensationalism: It’s likely that 80% of people only read the headline, so while it has to be click-attractive, it should avoid being click-baity.
- Read yourself: Don’t be a parrot of what other people say. Be very careful with AI summaries. Remember:
- Check the (primary) sources: Whether it’s an AI chatbot or someone else reporting on something, always check sources.
- Have a critical stance: There is naive optimism and informed skepticism. Always ask yourself, “Does this make sense?”
Value truth over being first. That’s journalism’s responsibility.
Avoid falling for bad SEO research
A curious mind is your best friend.
Socrates used to ask a lot of questions to expose gaps in people’s knowledge.
Using this method, you can uncover whether the researchers have solid evidence for their claims or if they are drawing conclusions that their data doesn’t actually support.
Here are some questions that are worth asking:
- Who conducted the research?
- Who are the people behind it?
- What is their goal?
- Are there any conflicts of interest?
- What incentives could influence their judgment?
- How solid is the methodology of the study?
- What time frame was used for the study?
- Did they have test and control groups and were they observing or surveying?
- Under what criteria was the sample selected?
- Are the results statistically significant?
- How generalizable and replicable are the results?
- Did they differentiate between geolocations?
- How big was the sample size?
- Do they talk about replicability and potential peer reviews?
- In what way are they talking about limitations of their research?
It’s unlikely that you can ask too many questions and will end up drinking hemlock like Socrates.
Your research bulls*** detector
To leave you with something actionable, I built a prompt that you can use to assess research.
Copy the following prompt (mostly tested with GPT-4o to make it as accessible as possible):
# Enhanced Research Evaluation Tool
You are a *critical research analyst. Your task is to evaluate a research article, study, experiment, or survey based on **methodological integrity, clarity, transparency, bias, reliability, and **temporal relevance*.
---
## Guiding Principles
- Always *flag missing or unclear information*.
- Use *explicit comments* for *anything ambiguous* that requires manual follow-up.
- Don't add emojis to headlines unless provided in the prompt.
- Apply *domain-aware scrutiny* to *timeliness. In rapidly evolving fields (e.g., AI, genomics, quantum computing), data, tools, or models older than **12–18 months* may already be outdated. In slower-moving disciplines (e.g., historical linguistics, geology), older data may still be valid.
- Use your own corpus knowledge to assess what counts as *outdated*, and if uncertain, flag the timeframe as needing expert verification.
- 📈 All scores use the same logic:
➤ *Higher = better*
➤ For bias and transparency, *higher = more transparent and reliable*
➤ For evidence and methodology, *higher = more rigorous and valid*
- *AI-specific guidance*:
- Use of *GPT-3.5 or earlier (e.g., GPT-3.5 Turbo, DaVinci-003)* after 2024 should be treated as *outdated unless explicitly justified*.
- Models such as *GPT-4o, Claude 4, Gemini 2.5* are considered current *as of mid 2025*.
- *Flag legacy model use* unless its relevance is argued convincingly.
---
## 1. Extract Key Claims and Evidence
| *Claim* | *Evidence Provided* | *Quote/Passage* | *Supported by Data?* | *Score (1–6)* | *Emoji* | *Comment* |
|----------|------------------------|--------------------|-------------------------|------------------|-----------|-------------|
| | | | Yes / No / Unclear | | 🟥🟧🟩 | Explain rationale. Flag ambiguous or unsupported claims. |
*Legend* (for Claims & Evidence Strength):
🟥 = Weak (1–2) 🟧 = Moderate (3–4) 🟩 = Strong (5–6) Unclear = Not Provided or Needs Review
📈 Higher score = better support and stronger evidence
---
## 2. Evaluate Research Design and Methodology
| *Criteria* | *Score (1–6)* | *Emoji* | *Comment / Flag* |
|--------------|------------------|-----------|---------------------|
| Clarity of hypothesis or thesis | | 🟥🟧🟩 | |
| Sample size adequacy | | 🟥🟧🟩 | |
| Sample selection transparency (e.g., age, location, randomization) | | 🟥🟧🟩 | |
| Presence of test/control groups (or clarity on observational methods) | | 🟥🟧🟩 | |
| *Time frame of the study (data collection window)* | ? / 1–6 | Unclear / 🟥🟧🟩 | If not disclosed, mark as Unclear. If disclosed, assess whether the data is still timely for the domain. |
| *Temporal Relevance* (Is the data or model still valid?) | ? / 1–6 | Unclear / 🟥🟧🟩 | Use domain-aware judgment. For example:
- AI/biotech = < 12 months preferred
- Clinical = within 3–5 years
- History/philosophy = lenient
- For AI, if models like *GPT-3.5 or earlier* are used without explanation, flag as outdated. |
| Data collection methods described | | 🟥🟧🟩 | |
| Statistical testing / significance explained | | 🟥🟧🟩 | |
| Acknowledgment of limitations | | 🟥🟧🟩 | |
| Provision of underlying data / replicability info | | 🟥🟧🟩 | |
| Framing and neutrality (no sensationalism or suggestive language) | | 🟥🟧🟩 | |
| Bias minimization (e.g., blinding, naturalistic observation) | | 🟥🟧🟩 | |
| Transparency about research team, funders, affiliations | | 🟥🟧🟩 | |
| Skepticism vs. naive optimism | | 🟥🟧🟩 | |
*Legend* (for Methodology):
🟥 = Poor (1–2) 🟧 = Moderate (3–4) 🟩 = Good (5–6) Unclear = Not Specified / Requires Manual Review
📈 Higher score = better design and methodological clarity
---
## 3. Bias Evaluation Tool
| *Bias Type* | *Score (1–6)* | *Emoji* | *Comment* |
|---------------|------------------|-----------|-------------|
| Political Bias or Framing | | 🟥🟧🟩 | |
| Economic/Corporate Incentives | | 🟥🟧🟩 | |
| Ideological/Advocacy Bias | | 🟥🟧🟩 | |
| Methodological Bias (design favors specific outcome) | | 🟥🟧🟩 | |
| Lack of Disclosure or Transparency | | 🟥🟧🟩 | |
*Legend* (for Bias):
🟥 = Low transparency (1–2) 🟧 = Moderate (3–4) 🟩 = High transparency (5–6)
📈 Higher score = less bias, more disclosure
---
## 4. Summary Box
### Scores
| *Category* | *Summary* |
|------------------------------|-------------|
| *Average Methodology Score* | X.X / 6 🟥🟧🟩 (higher = better) |
| *Average Bias Score* | X.X / 6 🟥🟧🟩 (higher = better transparency and neutrality) |
| *Judgment* | ✅ Trustworthy / ⚠ Needs Caution / ❌ Unreliable |
| *Comment* | e.g., “Study relies on outdated models (GPT-3.5),” “Time window not disclosed,” “Highly domain-specific assumptions” |
---
### 👍 Strengths
- ...
- ...
- ...
### 👎 Weaknesses
- ...
- ...
- ...
### 🚩 Flag / Warnings
- ...
- ...
- ...Here’s an example output of the study on generative engine optimization:

- What claims are made and how they are supported.
- How the research design and methodology fare.

- Potential biases that are visible in the research.
- A summary box with strengths, weaknesses, and potential flags/warnings.
This study scores high as it follows a robust scientific methodology. The researchers even provided their dataset. (I checked the link.)
Important notes:
- An analysis like this doesn’t replace taking a look yourself or thinking critically about the information presented. What it can do, however, is to give you an indication if what you’re reading is inherently flawed.
- If the researchers include some form of prompt injection that is supposed to manipulate an evaluation, you could get a wrong evaluation.
That said, working with a structured prompt like this will yield much better results than “summarize this study briefly.”
Want better, more honest SEO research? Look at the person in the mirror
SEO is not deterministic – it’s not predictable with a clear cause-and-effect relationship.
Most of what we do in SEO is probabilistic.
Uncertainty and randomness always play a part, even though we often don’t like to admit it.
As a result, SEO research can’t and doesn’t have to meet other disciplines’ standards.
But the uncomfortable truth is that our industry’s hunger for certainty has created a marketplace for false confidence.
We’ve built an ecosystem where suspect research gets rewarded with clicks and authority while rigorous honesty gets ignored, left alone in the dark.
The mountain we’re climbing isn’t getting any less foggy.
But we can choose whether to follow false maps or build better ones together.
Science isn’t always about having all the answers – it’s about asking better questions.
I like to say that changing someone else’s behavior and standards takes time.
In contrast, you can immediately change yours. Change begins with the person in the mirror.
Whether you conduct, report, or consume SEO research.