3 Ways to Responsibly Manage Multi-Agent Systems
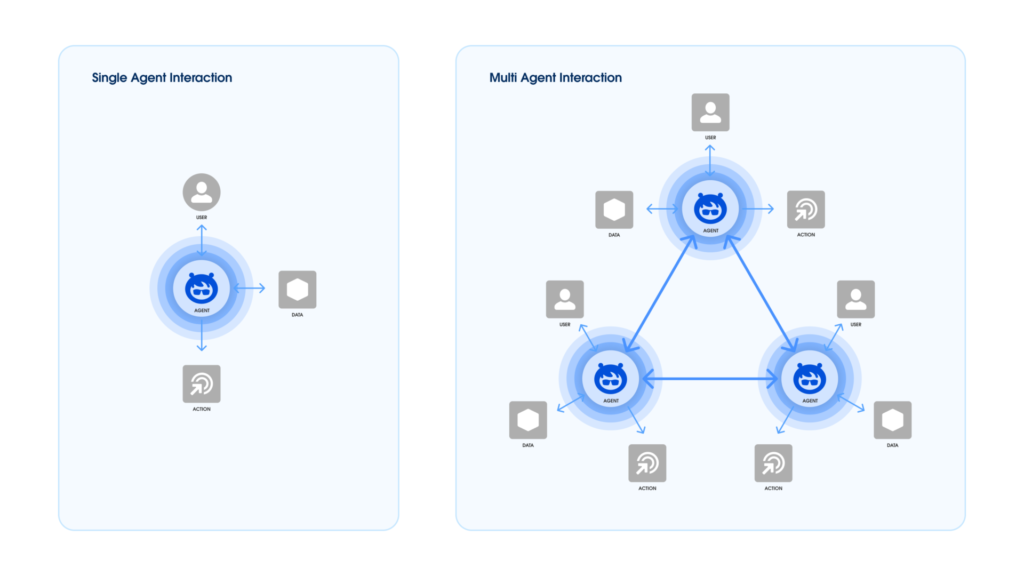
As autonomous AI systems gain traction, businesses increasingly depend on networks of interacting agents to drive complex processes and decisions. But with the rise of these AI “teams” come questions about how best to ensure they operate responsibly, ethically, and effectively. Just as companies govern human teams, autonomous systems also require frameworks to manage risk, […]
3 Ways to Responsibly Manage Multi-Agent Systems Read More »