Whether you are administering traditional VMs, GKE clusters, or a combination of the two, it’s important to automate as many of your operational tasks as possible in the most cost-effective manner, and where possible, get rid of them altogether!
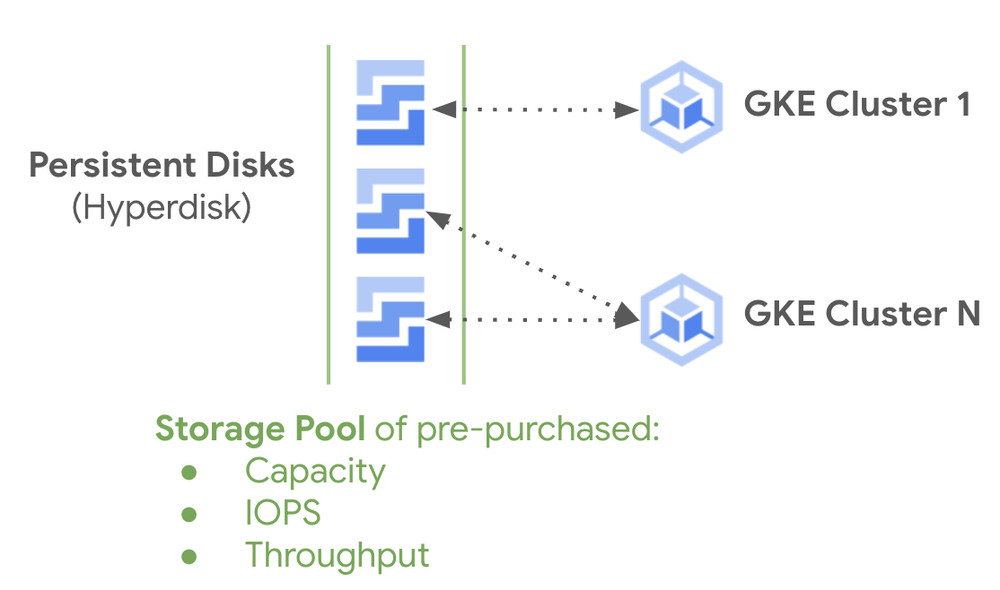
Hyperdisk is a next-generation network attached block storage service, and Hyperdisk Storage Pools are a pre-purchased collection of capacity, throughput, and IOPS that you can then provision to your applications as needed. When you place Hyperdisk block storage disks in storage pools, you can share capacity and performance among all the disks in a pool, optimizing for both operations and cost. Hyperdisk Storage Pools help you lower your storage-related Total Cost of Ownership (TCO) by as much as 30-50%, and as of Google Kubernetes Engine (GKE) 1.29.2 are available for use on GKE!
This is made possible by Storage Pools’ thin provisioning, which allows you to only consume capacity provisioned inside the pool when data is written, and not when pool disks are provisioned. Capacity, IOPS, and throughput are purchased at the pool-level and consumed by the disks in the pool on an as-needed basis, allowing you to share resources when needed rather than provisioning each disk for peak load regardless of whether it ever sees that load:
Why Hyperdisk?
As the next generation of persistent block storage on Google Cloud, Hyperdisk differs from traditional persistent disks in that it allows for IOPS and throughput configuration in addition to capacity. Furthermore, it’s possible to tune the performance, even after initial configuration, of the disks to your exact application needs, removing excess capacity and unlocking cost savings.
What about Storage Pools?
Storage Pools, meanwhile, let you share a pool of thin-provisioned capacity across a number of Hyperdisks in a single project that all reside in the same zone known as an “Advanced Capacity” storage pool. You purchase the capacity up front and only consume it on data that is written, instead of storage capacity that is provisioned. You can do the same with IOPS and throughput in what’s known as an “Advanced Capacity & Advanced Performance” storage pool.
Together, Hyperdisk + Storage Pools lower your block storage TCO and move management tasks from the disk-level to the pool-level, where changes are absorbed by all disks in the pool. A storage pool has a minimum capacity of 10TB and is a zonal resources that must contain a Hyperdisk of the same type (Balanced or Throughput).
Hyperdisk + Storage Pools on GKE
Starting on GKE 1.29.2 you can now create Hyperdisk Balanced boot disks and Hyperdisk Balanced or Hyperdisk Throughput attached disks on GKE nodes inside storage pools.
Let’s say you have a demanding stateful application running in us-central1-a, and you want the ability to tune the performance for your workload. You choose Hyperdisk Balanced as the block storage for the workload. Instead of attempting to right-size each disk in your application, you use a Hyperdisk Balanced Advanced Capacity, Advanced Performance Storage Pool. You purchase the capacity and performance up front. Pool capacity is only consumed when your application writes data to the disks, and pool performance is consumed when IOPS/throughput usage is observed by the disks in the storage pool. You must first create the storage pool(s) before you create the Hyperdisks inside them.
To create an Advanced Capacity, Advanced Performance Storage Pool, use the following gcloud command:
<ListValue: [StructValue([(‘code’, ‘gcloud compute storage-pools create pool-us-central1-a –provisioned-capacity=10tb –storage-pool-type=hyperdisk-balanced –zone=us-central1-a –project=my-project-id –capacity-provisioning-type=advanced –performance-provisioning-type=advanced –provisioned-iops=10000 –provisioned-throughput=1024’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e847056f460>)])]>
Storage Pools can also be created via the Pantheon UI. See Create Storage Pools for details.
If your GKE nodes are using Hyperdisk Balanced as boot disks, you can provision your node boot disks in the storage pool as well. You can configure this on cluster or node-pool creation, or on node-pool update. To provision your Hyperdisk Balanced node boot disks in your storage pool on cluster creation, you can use the following gcloud command, or use the Pantheon UI. Note that the machine-type of the nodes must support Hyperdisk Balanced, and your Storage Pool must be created in the same zone as your cluster.
<ListValue: [StructValue([(‘code’, ‘gcloud container clusters create sp-cluster –zone=us-central1-a –project=my-project –machine-type=c3-standard-4 –disk-type=”hyperdisk-balanced” –storage-pools= “projects/my-project-id/zones/us-central1-a/storagePools/pool-us-central1-a”‘), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e847056fa60>)])]>
To provision the Hyperdisk Balanced disks used by your stateful application in your storage pool, you need to specify your storage pool through the storage-pools StorageClass parameter. The StorageClass is then used in a Persistent Volume Claim (PVC) to provision the Hyperdisk Balanced volume that will be used by your application.
The StorageClass can optionally specify the provisioned-throughput-on-create and provisioned-iops-on-create parameters. If provisioned-throughput-on-create and provisioned-iops-on-create are left unspecified, the volume will have a default of 3000 IOPS and 140Mi throughput. Only IOPS and Throughput values that are in excess of these default values will consume any IOPS or Throughput from the storage pool.
The acceptable values for IOPS / Throughput differ depending on the disk size. Please see IOPS and Throughput Provisioning for Hyperdisk for details.
<ListValue: [StructValue([(‘code’, ‘apiVersion: storage.k8s.io/v1rnkind: StorageClassrnmetadata:rn name: storage-pools-scrnprovisioner: pd.csi.storage.gke.iornvolumeBindingMode: WaitForFirstConsumerrnallowVolumeExpansion: truernparameters:rn type: hyperdisk-balancedrn provisioned-throughput-on-create: “180Mi”rn provisioned-iops-on-create: “4000”rn storage-pools: projects/my-project-id/zones/us-central1-a/storagePools/pool-us-central1-a’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e847056f280>)])]>
Volumes provisioned with this StorageClass will only consume 40MiB of throughput from the StoragePool, and 1000 IOPS from the Storage Pool.
Next, create a PVC that references the storage-pools-sc StorageClass.
<ListValue: [StructValue([(‘code’, ‘apiVersion: v1rnkind: PersistentVolumeClaimrnmetadata:rn name: my-pvcrnspec:rn storageClassName: storage-pools-scrn accessModes:rn – ReadWriteOncern resources:rn requests:rn storage: 2048Gi’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e847056fbe0>)])]>
The storage-pools-sc StorageClass uses Volume Binding Mode: WaitForFirstConsumer, which will delay the binding and provisioning of a PersistentVolume until a Pod using the PVC is created.
Lastly, use these Hyperdisk Volumes in your Stateful application by using the PVC above. Your application needs to be scheduled to a node pool with machines that can attach Hyperdisk Balanced.
<ListValue: [StructValue([(‘code’, ‘apiVersion: apps/v1rnkind: Deploymentrnmetadata:rn name: postgresrnspec:rn selector:rn matchLabels:rn app: postgresrn template:rn metadata:rn labels:rn app: postgresrn spec:rn nodeSelector:rn cloud.google.com/machine-family: c3rn containers:rn – name: postgresrn image: postgres:14-alpinern args: [ “sleep”, “3600” ]rn volumeMounts:rn – name: sdk-volumern mountPath: /usr/share/data2/rn volumes:rn – name: sdk-volumern persistentVolumeClaim:rn claimName: my-pvc’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e847056fb20>)])]>
The postgres deployment uses nodeSelectors to ensure the pods get scheduled to nodes with C3 machines type, which supports attaching Hyperdisk Balanced.
Now you should be able to see your Hyperdisk Balanced volume is provisioned in your storage pool.
<ListValue: [StructValue([(‘code’, ‘kubectl get pvc my-pvcrnNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGErnmy-pvc Bound pvc-1ff52479-4c81-4481-aa1d-b21c8f8860c6 2Ti RWO storage-pools-sc 2m24srnrngcloud compute storage-pools list-disks pool-us-us-central1-a –zone=us-central1-arnNAME STATUS PROVISIONED_IOPS PROVISIONED_THROUGHPUT SIZE_GB USED_GBrnpvc-1ff52479-4c81-4481-aa1d-b21c8f8860c6 READY 4000 180 2048 0’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e847056f040>)])]>
Next steps
Having a Storage Pools + Hyperdisk strategy for GKE will allow you to maximize storage cost savings and efficiency for your stateful applications. To get started please visit the links below to create your storage pools then apply them in GKE clusters:
Create a Hyperdisk Storage Pool
Hyperdisk Storage Pools: Simplify block storage management and lower TCO

