Amazon Q Business is a fully managed, generative artificial intelligence (AI)-powered assistant that helps enterprises unlock the value of their data and knowledge. With Amazon Q, you can quickly find answers to questions, generate summaries and content, and complete tasks by using the information and expertise stored across your company’s various data sources and enterprise systems. At the core of this capability are native data source connectors that seamlessly integrate and index content from multiple repositories into a unified index. This enables the Amazon Q large language model (LLM) to provide accurate, well-written answers by drawing from the consolidated data and information. The data source connectors act as a bridge, synchronizing content from disparate systems like Salesforce, Jira, and SharePoint into a centralized index that powers the natural language understanding and generative abilities of Amazon Q.
Customers appreciate that Amazon Q Business securely connects to over 40 data sources. While using their data source, they want better visibility into the document processing lifecycle during data source sync jobs. They want to know the status of each document they attempted to crawl and index, as well as the ability to troubleshoot why certain documents were not returned with the expected answers. Additionally, they want access to metadata, timestamps, and access control lists (ACLs) for the indexed documents.
We are pleased to announce a new feature now available in Amazon Q Business that significantly improves visibility into data source sync operations. The latest release introduces a comprehensive document-level report incorporated into the sync history, providing administrators with granular indexing status, metadata, and ACL details for every document processed during a data source sync job. This enhancement to sync job observability enables administrators to quickly investigate and resolve ingestion or access issues encountered while setting up an Amazon Q Business application. The detailed document reports are persisted in the new SYNC_RUN_HISTORY_REPORT log stream under the Amazon Q Business application log group, so critical sync job details are available on-demand when troubleshooting.
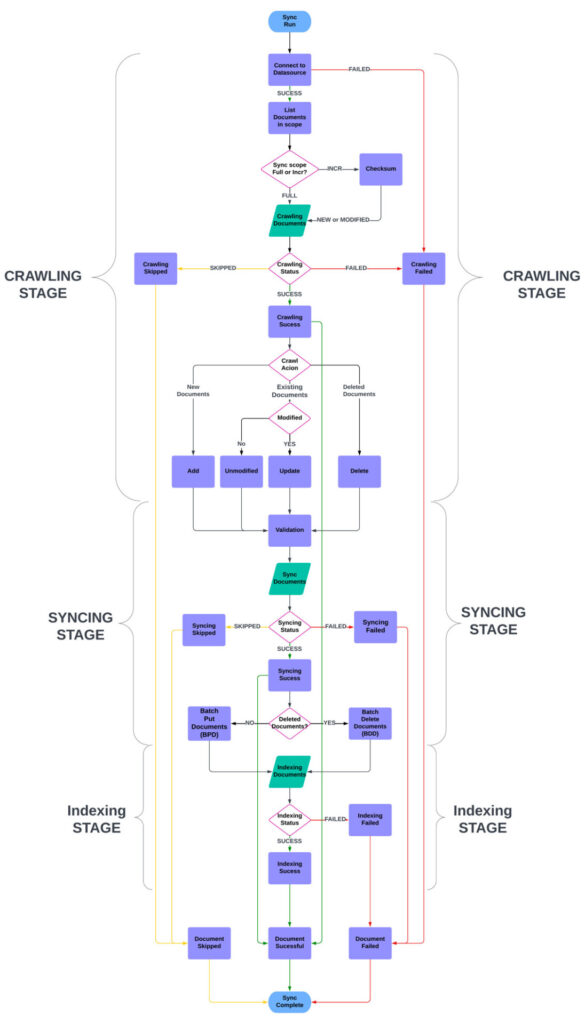
Lifecycle of a document in a data source sync run job
In this section, we examine the lifecycle of a document within a data source sync in Amazon Q Business. This provides valuable insight into the sync process. The data source sync comprises three key stages: crawling, syncing, and indexing. Crawling involves the connector connecting to the data source and extracting documents meeting the defined sync scope according to the data source configuration. These documents are then synced to Amazon Q Business during the syncing phase. Finally, indexing makes the synced documents searchable within the Amazon Q Business environment.
The following diagram shows a flowchart of a sync run job.
Crawling stage
The first stage is the crawling stage, where the connector crawls all documents and their metadata from the data source. During this stage, the connector also compares the checksum of the document against the Amazon Q index to figure out if a particular document needs to be added, modified, or deleted from the index. This operation corresponds to the CrawlAction field in the sync run history report.
If the document is unmodified, it is marked as UNMODIFIED and skipped in the rest of the stages. If any document fails in the crawling stage, for example due to throttling errors, broken content, or if the document size is too big, that document is marked as failed in the sync run history report with the CrawlStatus as FAILED. If the document was skipped due to any validation errors, its CrawlStatus is marked as SKIPPED. These documents are not sent forward to the next stage. All successful documents are marked as SUCCESS and are sent forward.
We also capture the ACLs and metadata on each document in this stage to be able to add it to the sync run history report.
Syncing stage
During the syncing stage, the document is sent to Amazon Q Business ingestion service APIs like BatchPutDocument and BatchDeleteDocument. After a document is submitted to these APIs, Amazon Q Business runs validation checks on the submitted documents. If any document fails these checks, its SyncStatus is marked as FAILED. If there is an irrecoverable error for a particular document, it is marked as SKIPPED and other documents are sent forward.
Indexing stage
In this step, Amazon Q Business parses the document, processes it according to its content type, and persists it in the index. If the document fails to be persisted, its IndexStatus is marked as FAILED; otherwise, it is marked as SUCCESS.
After the statuses of all the stages have been captured, we emit these statuses as an Amazon Cloudwatch event to the customer’s AWS account.
Key features and benefits of document-level reports
The following are the key features and benefits of the new document level report in Amazon Q Business applications:
Enhanced sync run history page – A new Actions column has been added to the sync run history page, providing access to the document-level report for each sync run.
Dedicated log stream – A new log stream named SYNC_RUN_HISTORY_REPORT has been created in the Amazon Q Business CloudWatch log group, containing the document-level report.
Comprehensive document information – The document-level report includes the following information for each document.
Document ID – This is the document ID that is inherited directly from the data source or mapped by the customer in the data source field mappings.
Document title – The title of the document is taken from the data source or mapped by the customer in the data source field mappings.
Consolidated document status (SUCCESS, FAILED, or SKIPPED) – This is the final consolidated status of the document. It can have a value of SUCCESS, FAILED, or SKIPPED. If the document was successfully processed in all stages, then the value is SUCCESS. If the document has failed or was skipped in any of the stages, then the value of this field will be FAILED or SKIPPED.
Error message (if the document failed) – This field contains the error message with which a document failed. If a document was skipped due to throttling errors, or any internal errors, this will be shown in the error message field.
Crawl status – This field denotes whether the document was crawled successfully from the data source. This status correlates to the syncing-crawling state in the data source sync.
Sync status – This field denotes whether the document was sent for syncing successfully. This correlates to the syncing-indexing state in the data source sync.
Index status – This field denotes whether the document was successfully persisted in the index.
ACLs – This field contains a list of document-level permissions that were crawled from the data source. The details of each element in the list are:
Global name: This is the email/username of the user. This field is mapped across multiple data sources. For example, if a user has 3 data sources – Confluence, Sharepoint and Gmail with the local user ID as confluence_user, sharepoint_user and gmail_user respectively, and their email address user@email.com is the globalName in the ACL for all of them; then Amazon Q Business understands that all of these local user IDs map to the same global name.
Name: This is the local unique ID of the user which is assigned by the data source.
Type: This field indicates the principal type. This can be either USER or GROUP.
Is Federated: This is a boolean flag which indicates whether the group is of INDEX level (true) or DATASOURCE level (false).
Access: This field indicates whether the user has access allowed or denied explicitly. Values can be either ALLOWED or DENIED.
Data source ID: This is the data source ID. For federated groups (INDEX level), this field will be null.
Metadata – This field contains the metadata fields (other than ACL) that were pulled from the data source. This list also includes the metadata fields mapped by the customer in the data source field mappings as well as extra metadata fields added by the connector.
Hashed document ID (for troubleshooting assistance) – To safeguard your data privacy, we present a secure, one-way hash of the document identifier. This encrypted value enables the Amazon Q Business team to efficiently locate and analyze the specific document within our logs, should you encounter any issue that requires further investigation and resolution.
Timestamp – The timestamp indicates when the document status was logged in CloudWatch.
In the following sections, we explore different use cases for the logging feature.
Troubleshoot “Sorry, I could not find relevant information” with the new logging feature
The new document-level logging feature in Amazon Q Business can help troubleshoot common issues related to the “Sorry, I could not find relevant information to complete your request” response.
Let’s explore an example scenario. A mutual funds manager uses Amazon Q Business chat for knowledge retrieval and insights extraction across their enterprise data stores. When the fund manager asks, “What is the CAGR of the multi-asset fund?” in the Amazon Q chat, they receive the “Sorry, I could not find relevant information to complete your request” response.
As the administrator managing their Amazon Q Business application, you can troubleshoot the issue using the following approach with the new logging feature. First, you want to determine whether the multi-asset fund document was successfully indexed in the Amazon Q Business application. Next, you need to verify if the fund manager’s user account has the required permission to read the information from the multi-asset fund document. Amazon Q Business enforces the document permissions configured in its data source, and you can use this new feature to verify that the document ACL settings are synced in the Amazon Q Business application index.
You can use the following CloudWatch query string to check the document ACL settings:
This query filter uses the per-document-level logging stream SYNC_RUN_HISTORY_REPORT, and displays the document title and its associated ACL settings. By verifying the document indexing and permissions, you can identify and resolve potential issues that may be causing the “Sorry, I could not find relevant information” response.
The following screenshot shows an example result.
Determine the optimal boosting duration for recent documents in using document-level reporting
When it comes to generating accurate answers, you may want to fine-tune the way Amazon Q prioritizes its content. For instance, you may prefer to boost recent documents over older ones to make sure the most up-to-date passages are used to generate an answer. To achieve this, you can use the business’s relevance tuning feature in Amazon Q Business to boost documents based on the last update date attribute, with a specified boosting duration. However, determining the optimal boosting period can be challenging when dealing with a large number of frequently changing documents.
You can now use the per-document-level report to obtain the _last_updated_at metadata field information for your documents, which can help you determine the appropriate boosting period. For this, you use the following CloudWatch Logs Insights query to retrieve the _last_updated_at metadata attribute for machine learning documents from the SYNC_RUN_HISTORY_REPORT log stream:
With the preceding query, you can gain insights into the last updated timestamps of your documents, enabling you to make informed decisions about the optimal boosting period. This approach makes sure your chat responses are generated using the most recent and relevant information, enhancing the overall accuracy and effectiveness of your Amazon Q Business implementation.
The following screenshot shows an example result.
Common document indexing observability and troubleshooting methods
In this section, we explore some common admin tasks for observing and troubleshooting document indexing using the new document-level reporting feature.
List all successfully indexed documents from a data source
To retrieve a list of all documents that have been successfully indexed from a specific data source, you can use the following CloudWatch query:
The following screenshot shows an example result.
List all successfully indexed documents from a data source sync job
To retrieve a list of all documents that have been successfully indexed during a specific sync job, you can use the following CloudWatch query:
The following screenshot shows an example result.
List all failed indexed documents from a data source sync job
To retrieve a list of all documents that failed to index during a specific sync job, along with the error messages, you can use the following CloudWatch query:
The following screenshot shows an example result.
List all documents that contains a particular user name ACL permission from an Amazon Q Business application
To retrieve a list of documents that have a specific user’s ACL permission, you can use the following CloudWatch Logs Insights query:
The following screenshot shows an example result.
List the ACL of an indexed document from a data source sync job
To retrieve the ACL information for a specific indexed document from a sync job, you can use the following CloudWatch Logs Insights query:
The following screenshot shows an example result.
List metadata of an indexed document from a data source sync job
To retrieve the metadata information for a specific indexed document from a sync job, you can use the following CloudWatch Logs Insights query:
The following screenshot shows an example result.
Conclusion
The newly introduced document-level report in Amazon Q Business provides enhanced visibility and observability into the document processing lifecycle during data source sync jobs. This feature addresses a critical need expressed by customers for better troubleshooting capabilities and access to detailed information about the indexing status, metadata, and ACLs of individual documents.
The document-level report is stored in a dedicated log stream named SYNC_RUN_HISTORY_REPORT within the Amazon Q Business application CloudWatch log group. This report contains comprehensive information for each document, including the document ID, title, overall document sync status, error messages (if any), along with its ACLs, and metadata information retrieved from the data sources. The data source sync run history page now includes an Actions column, providing access to the document-level report for each sync run. This feature significantly improves the ability to troubleshoot issues related to document ingestion and access control, and issues related to metadata relevance, and provides better visibility about the documents synced with an Amazon Q index.
To get started with Amazon Q Business, explore the Getting started guide. To learn more about data source connectors and best practices, see Configuring Amazon Q Business data source connectors.
About the authors
Aneesh Mohan is a Senior Solutions Architect at Amazon Web Services (AWS), bringing two decades of experience in creating impactful solutions for business-critical workloads. He is passionate about technology and loves working with customers to build well-architected solutions, focusing on the financial services industry, AI/ML, security, and data technologies.
Ashwin Shukla is a Software Development Engineer II on the Amazon Q for Business and Amazon Kendra engineering team, with 6 years of experience in developing enterprise software. In this role, he works on designing and developing foundational features for Amazon Q for Business.