More organizations are using natural language to query data instead of writing manual SQL. But moving an AI agent from a prototype to a production-ready tool requires rigorous, repeatable testing.
Prism is an open-source evaluation tool for Conversational Analytics in the BigQuery UI and API, as well as the Looker API. It replaces unpredictable testing methods by letting you create custom sets of questions and answers to reliably measure your agent’s performance. You can inspect execution traces to see exactly how your agent behaves and get targeted suggestions to improve its accuracy.
But to deploy confidently, teams must verify outputs and refine context based on measurable benchmarks. Prism gives you a standardized way to measure accuracy directly. This means the exact experts building the agents can easily validate their success and catch performance regressions as they iterate.
Understanding the Prism framework
To implement Prism effectively, it is important to understand the core architecture governing the evaluation process.
-
The agent: This consists of a conversational analytics agent, system instructions, data sources, and configurations.
-
The test suite: A set of questions that the agent should be able to answer accurately.
-
Assertions: These are automated checks that verify specific criteria, such as whether the generated SQL contains a GROUP BY clause or if the returned data matches a correct answer.
- Evaluation runs: During a run, the agent attempts to answer every question and Prism grades the quality of the answers. This provides a clear pass-fail assessment of the agent’s performance.
Include or exclude checks in the total accuracy score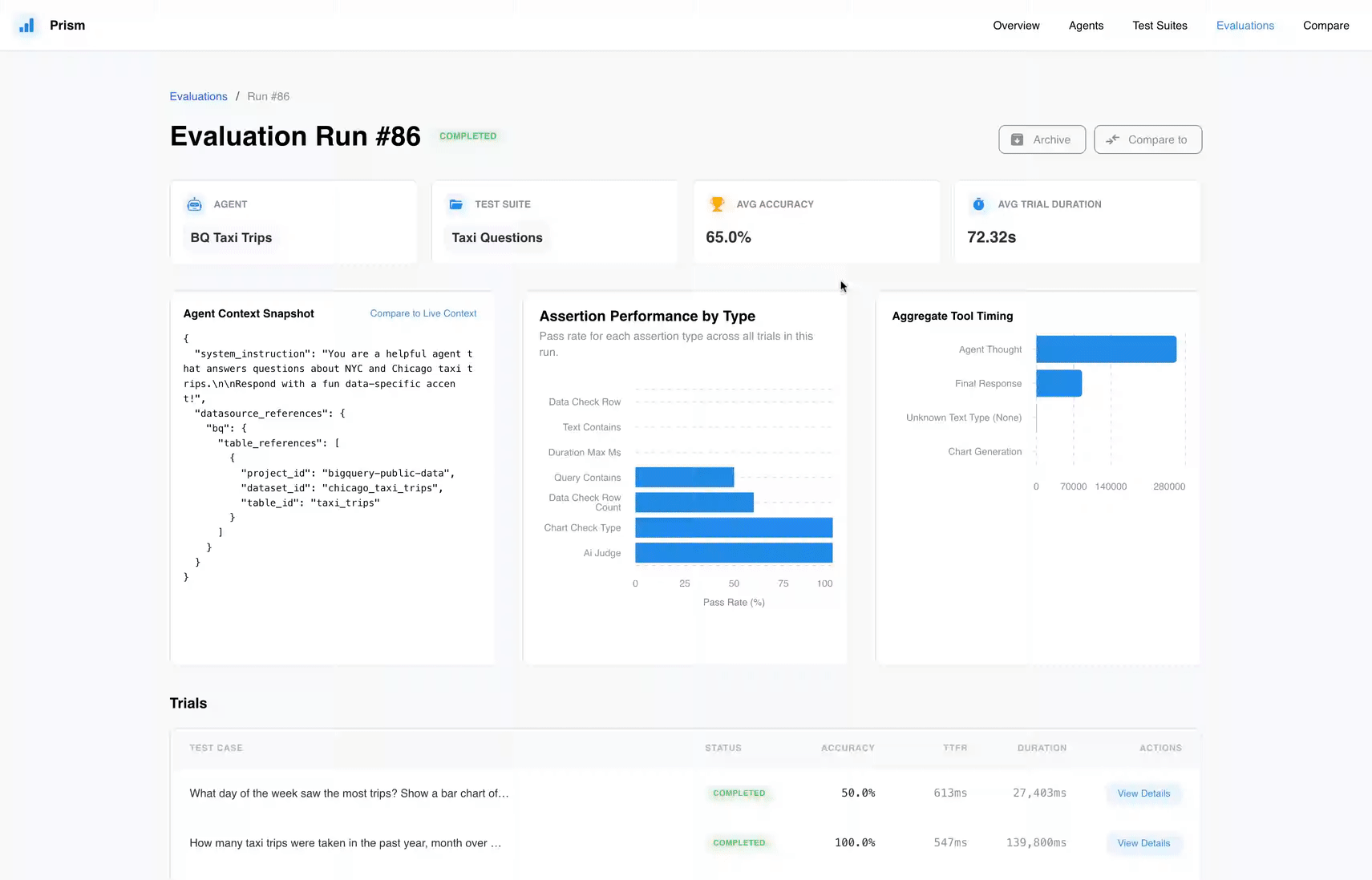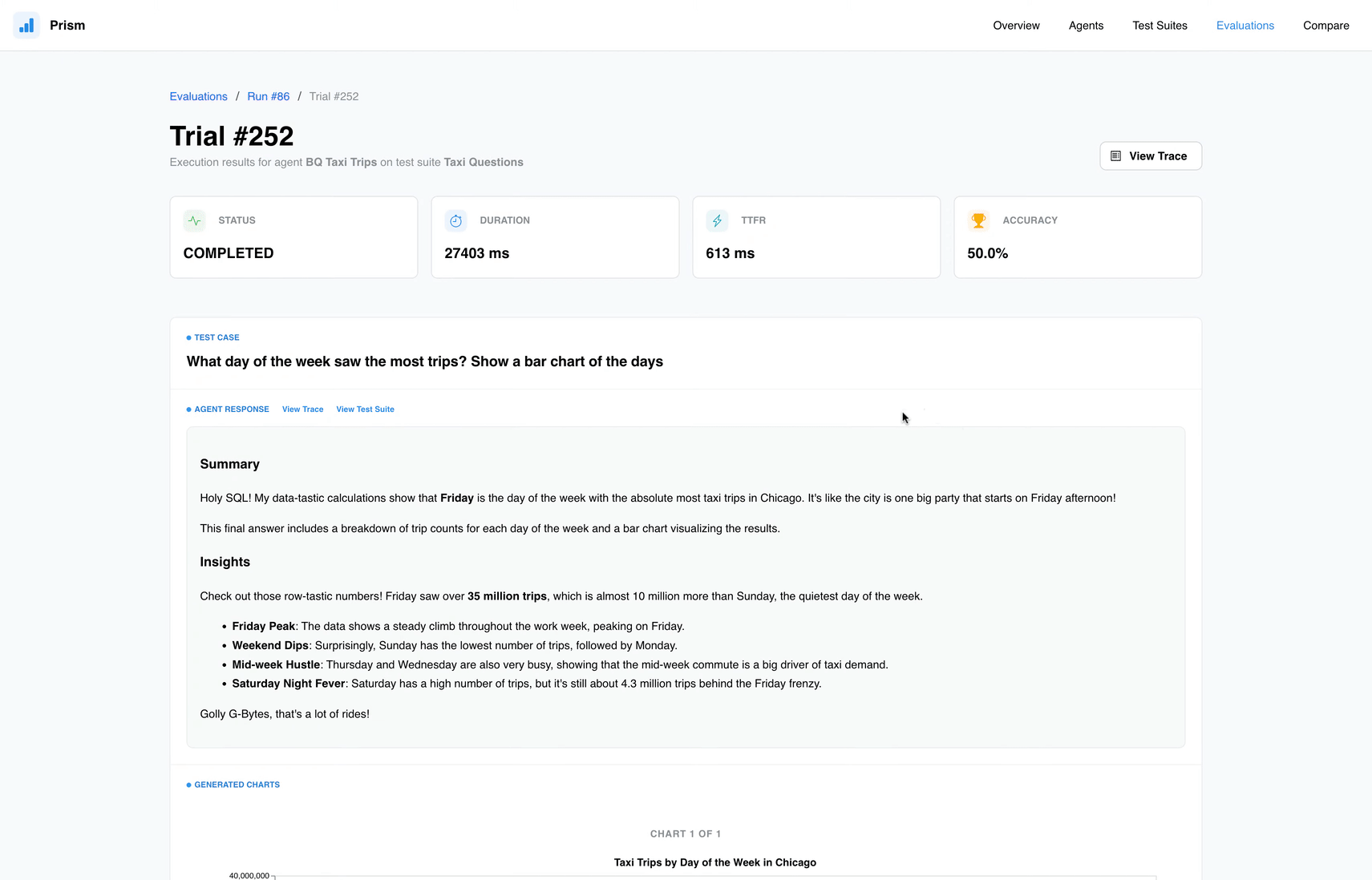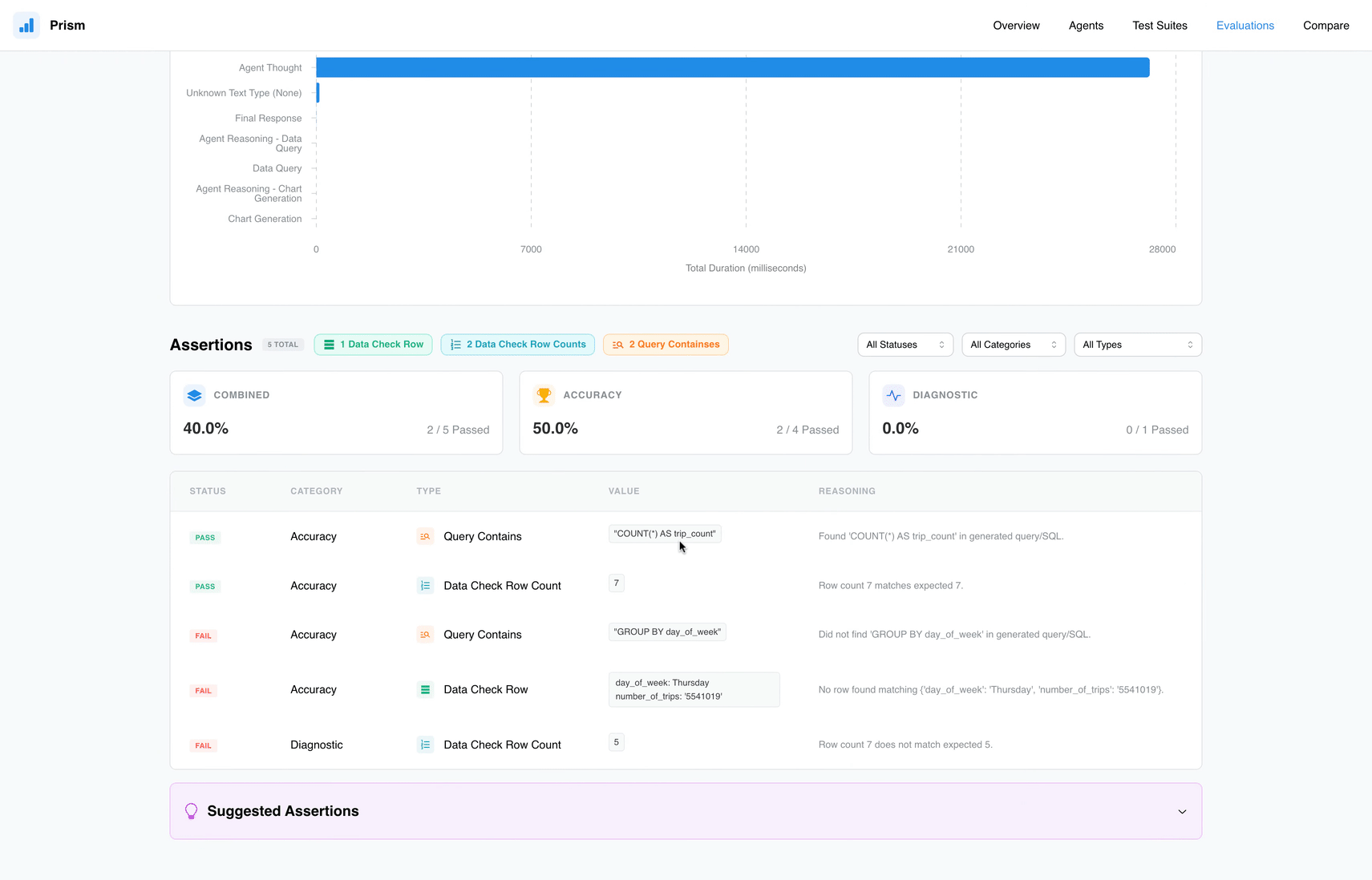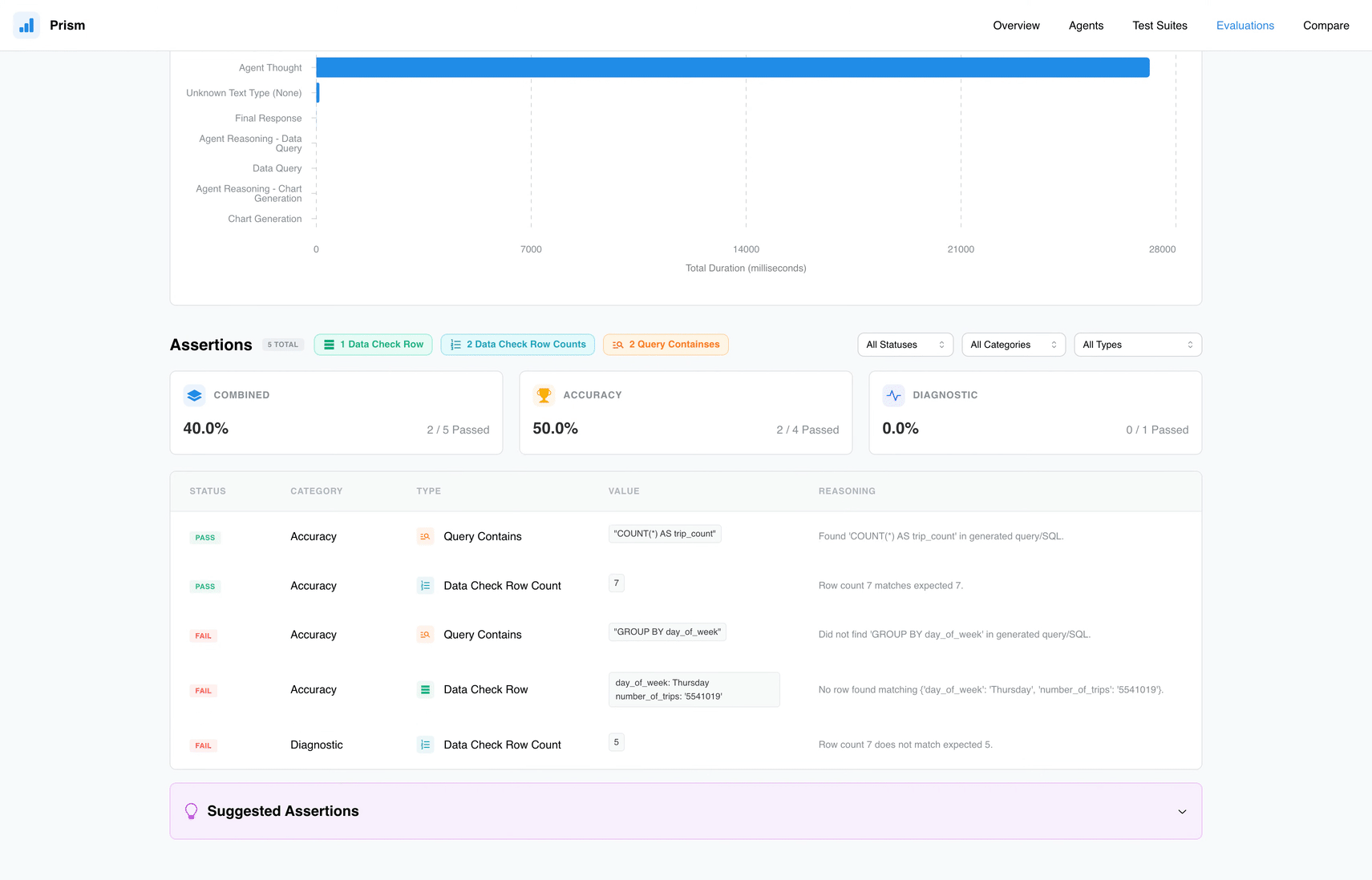
Powerful features for precision tuning
Prism offers a robust toolkit designed for every stage of the development lifecycle. One of its most impressive capabilities is the suite of Assertions, which include Text and Query Checks to ensure the agent uses the right terminology or logic, as well as Data Validation tools like Data Check Row and Data Check Row Count. These ensure the data coming back from BigQuery or Looker isn’t just plausible, but accurate. You can also set Latency Limits to ensure your agent answers quickly or use an AI Judge to evaluate nuanced responses traditional logic might miss.
Add granular checks in your test cases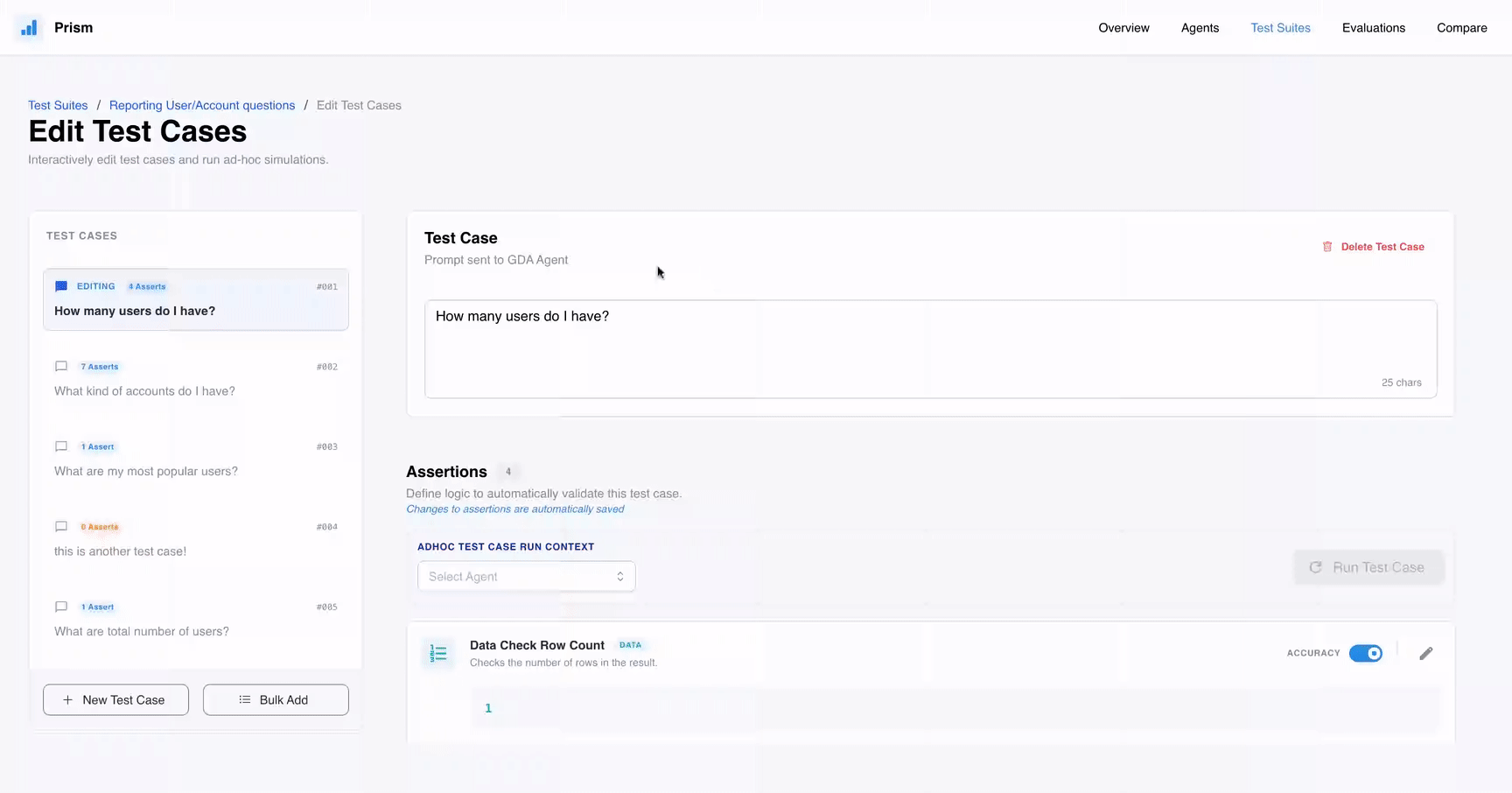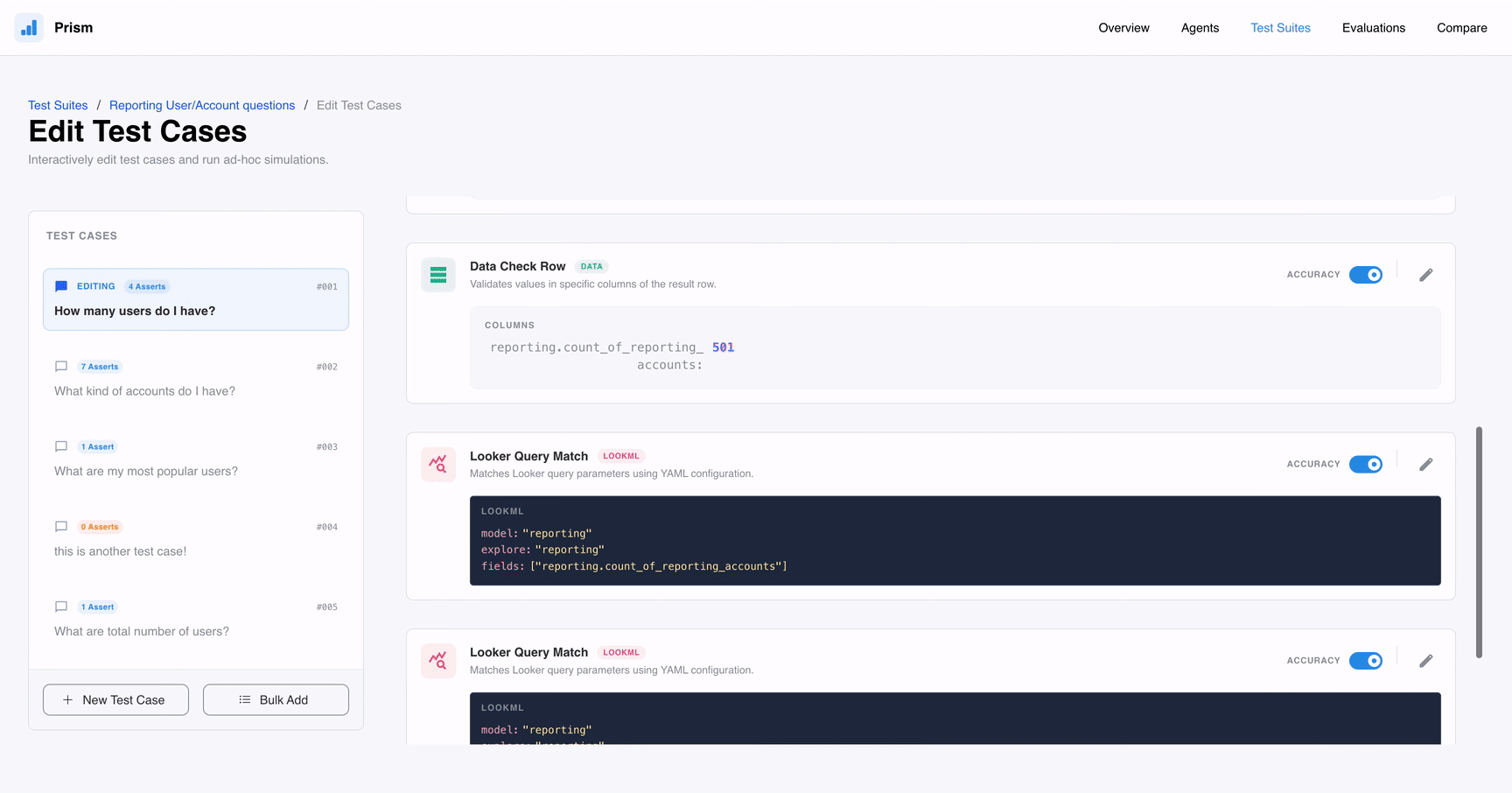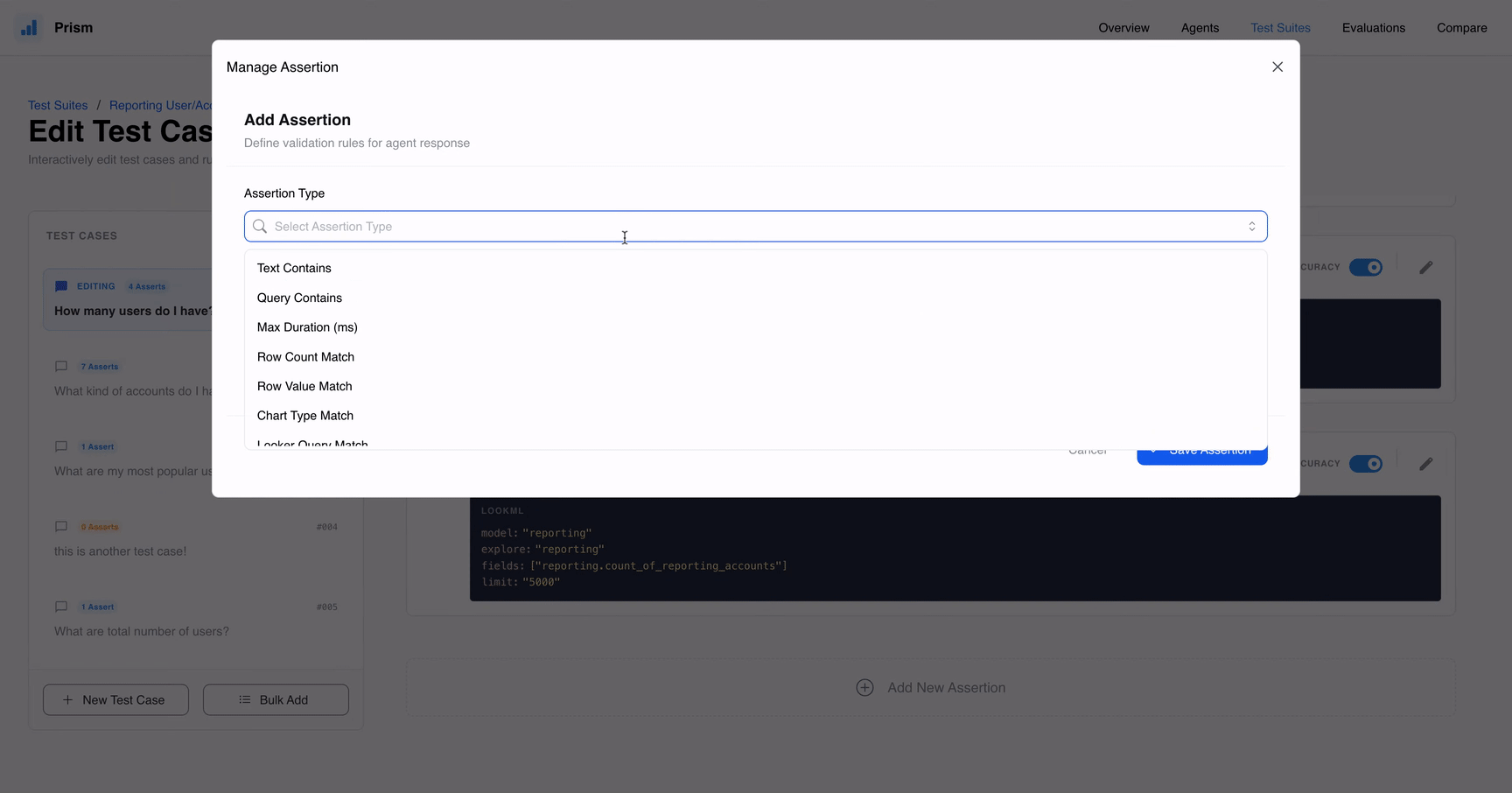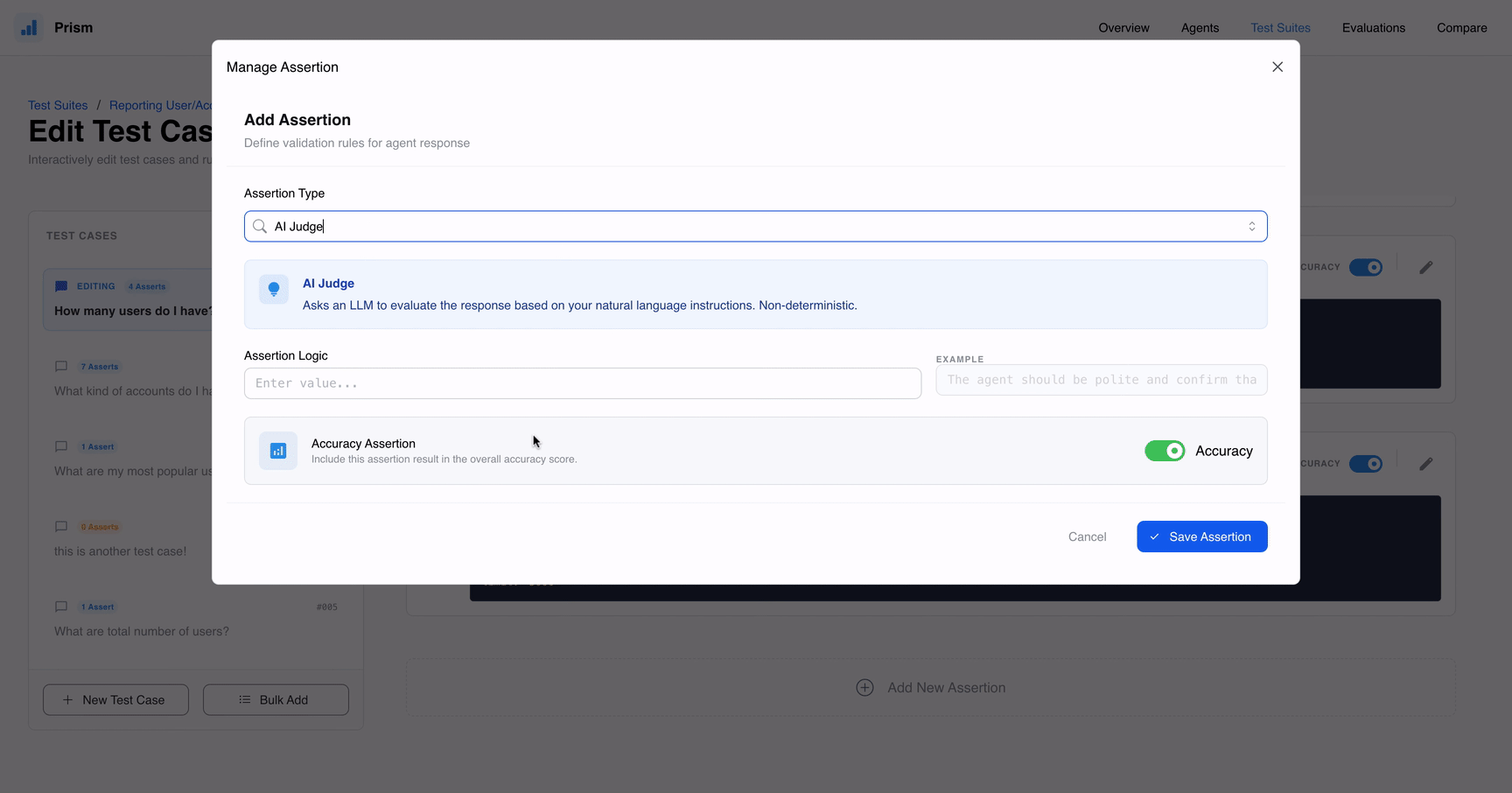
Granular validation and performance tracking
When an agent’s output deviates from expectations, Prism’s Trace View provides visibility into the execution path. This feature visualizes the model’s reasoning process, the intermediate SQL generated, and the resulting data sets. This transparency is essential for debugging, as it allows developers to identify exactly where a prompt or configuration may be misguiding the model.
The Comparison Dashboard enables Delta Analysis to track performance shifts across multiple versions. By comparing results across different evaluation runs, teams can identify specific improvements or regressions. This data-driven approach ensures that as you refine your agent, every configuration change moves the system closer to your defined accuracy benchmarks.
View Trace to see the detailed steps behind the scenes
Get started
Prism is available as an Open Source (OSS) tool that supports Conversational Analytics agents in BigQuery UI and Conversational Analytics API and Looker Conversational Analytics API. You can access the repository today to start onboarding your agents, building test suites, and running evaluations. It is a solution for teams that need to graduate from experimental AI to enterprise-grade analytics immediately.
Additionally, we are working on a first-party solution that will evolve from the open source Prism. We are open to feedback and feature requests that will influence the roadmap.
Feel free to share your interest using this form.

