Cloud Run has long provided developers with a straightforward, opinionated platform for running code. You can easily deploy request-driven web applications using Cloud Run services, or execute run-to-completion batch processing with Cloud Run jobs. However, as developers build more complex applications, like pipelines that process continuous streams of data or distributed AI workloads, they need an environment designed for continuous, background execution.
Estée Lauder Companies got just that with Cloud Run worker pools, which transform Cloud Run from a platform for web workloads and background tasks, to a platform for pull-based workloads. Cloud Run worker pools are now generally available.
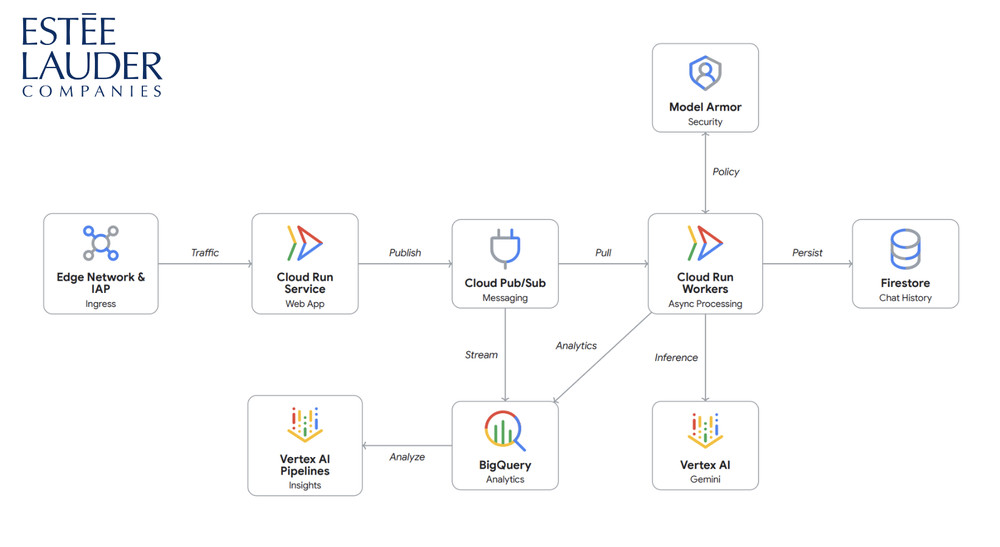
Estee Lauder Companies’ Rostrum platform is a polymorphic chat service for LLM-powered applications that originally ran as a standalone Cloud Run service. While the simple architecture worked for internal tools with predictable traffic, the team faced a major hurdle of the upcoming holiday shopping season for consumer-facing traffic. To launch their first consumer-facing generative AI application, Jo Malone London’s AI Scent Advisor, they needed an architecture that would sustain the load of AI prompts from thousands of simultaneous users.
In just a few weeks, Estee Lauder Companies migrated to a producer-consumer model using Cloud Run worker pools. The web tier, a FastAPI application deployed as Cloud Run Service acts as the producer, instantly publishing user messages to Cloud Pub/Sub. The worker pools deployments act as “always-on” consumers, pulling messages from the queue to handle LLM inference.
By decoupling the user-facing web tier from LLM operations, Estee Lauder Companies achieved:
-
100% message durability: Pub/sub acts as a buffer such that even during holiday spikes, no user message is lost.
-
Strong UI latency SLAs: Server-side rendering is decoupled from message processing load.
-
Minimal operations overhead: The team spent virtually no time managing servers, allowing them to focus on the user experience rather than infrastructure.
This modular architecture now serves as the blueprint for Estee Lauder Companies to rapidly launch specialized AI advisors across its diverse house of brands.
“The Jo Malone London AI Scent Advisor chains multiple LLM and tool calls — conversational discovery, deterministic scoring, copy generation — in a pipeline that had to run reliably at consumer scale without us managing infrastructure. Cloud Run worker pools was exactly the right primitive, and working directly with the product team as early adopters gave us the confidence to build on it ahead of GA. It’s now the foundation for us to bring AI advisors to brands across the Estée Lauder Companies portfolio.” – Chris Curro, Principal Machine Learning Engineer, The Estée Lauder Companies

Serverless for pull-based and distributed workloads
Traditional serverless models often force background work into an HTTP push format, which can lead to timeouts, overscaling, or message loss during traffic surges. Cloud Run worker pools solve this by providing an always-on environment where the worker pool instances pull tasks or messages from a queue at their own pace, providing built-in backpressure that protects your infrastructure from crashing under load.
Unlike Cloud Run services, worker pools are designed for workloads requiring non-HTTP protocols. When a worker pool is attached to a VPC network, every instance receives a private IP address. This enables high-performance L4 ingress, allowing you to host services previously incompatible with the Google Cloud serverless platform.
With the GA of worker pools, Cloud Run supports major new categories of workloads:
- Pull-based workloads: Worker pools provide a reliable environment for running and scaling workloads that continuously pull messages from queues like Pub/Sub, Kafka, Github Runners or Redis task queues.
- Distributed AI/ML workloads: Worker pools are a great fit for distributed LLM training or fine-tuning workloads. At GA, worker pools support NVIDIA L4 and RTX PRO 6000 (Blackwell) GPUs.

One of the most significant advantages of this new offering is its cost-efficiency, as worker pools can be approximately 40% cheaper than request-driven Services or Jobs for long-running background tasks.
Scaling pull-based workloads using Cloud Run External Metrics Autoscaler (CREMA)
Worker pools run a set of instances that do background work, but they still need a signal to scale. To bridge this gap, we recently built, and open-sourced, Cloud Run External Metrics Autoscaler (CREMA).
CREMA uses KEDA’s library of scalers – including Kafka, Pub/sub, Github Actions and Prometheus – to automatically scale your instances based on metrics emitted by these external sources. By smoothly handling traffic surges and scaling back to zero during idle periods, CREMA ensures you optimize both performance and cost
To start scaling, all you need to do is deploy CREMA as a Cloud Run service, and then define your scaling logic in a single YAML configuration file that instructs CREMA which external sources to monitor and which worker pool to scale.
Here is an example of what it looks like to automatically scale a worker pool based on GitHub Runner queue depth:
- code_block
- <ListValue: [StructValue([(‘code’, ‘apiVersion: crema/v1rnkind: CremaConfigrnmetadata:rn name: gh-demornspec:rn scaledObjects:rn – spec:rn scaleTargetRef:rn name: projects/example-project/locations/us-central1/workerpools/example-workerpoolrn triggers:rn – type: github-runnerrn metadata:rn owner: repo-ownerrn runnerScope: reporn repos: repo-namern targetWorkflowQueueLength: 1’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7fa27beed070>)])]>
Get started
You can deploy your first worker pool today by referring to the documentation. To implement advanced, queue-aware scaling, explore the CREMA open-source repository to connect your workloads to KEDA-supported scalers.
To implement high-performance distributed workloads using Cloud Run worker pools and External Metrics Autoscaling (CREMA), you can refer to the below examples for the use case of your choice.

