
Generative AI has transformed customer support, offering businesses the ability to respond faster, more accurately, and with greater personalization. AI agents, powered by large language models (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses.
In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences. Although the principles discussed are applicable across various industries, we use an automotive parts retailer as our primary example throughout this post.
By the end of this post, you’ll have a clear understanding of how to do the following:
Use Amazon Bedrock Agents to create intelligent, context-aware customer support bots
Integrate enterprise data sources, such as inventory management and catalog systems, with agents using AWS Lambda
Build customized chat interfaces using the Amazon Bedrock Agents API
Implement a solution that can instantly cross-reference product specifications with catalogs, check real-time inventory, and provide detailed information to the end-user
Solution overview
To illustrate the potential of this technology, consider an automotive parts retailer. In this industry, finding the right components can be challenging, because it often involves navigating extensive catalogs and complex compatibility requirements. An automotive retailer might use inventory management APIs to track stock levels and catalog APIs for vehicle compatibility and specifications. Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions.
The solution presented in this post takes approximately 15–30 minutes to deploy and consists of the following key components:
Amazon OpenSearch Service Serverless maintains three indexes: the inventory index, the compatible parts index, and the owner manuals index. These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results.
Amazon Bedrock Agents coordinates interactions between foundation models (FMs), knowledge bases, and user conversations. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information.
Amazon Bedrock Knowledge Bases enables you to use Retrieval Augmented Generation (RAG), a technique that enhances responses from LLMs by incorporating information from a data store. By setting up a knowledge base with your data sources, your application can query it to provide answers, either through direct quotes from the sources or through naturally generated responses based on the query results.
A web application serves as the frontend interface where users can initiate parts lookup requests.
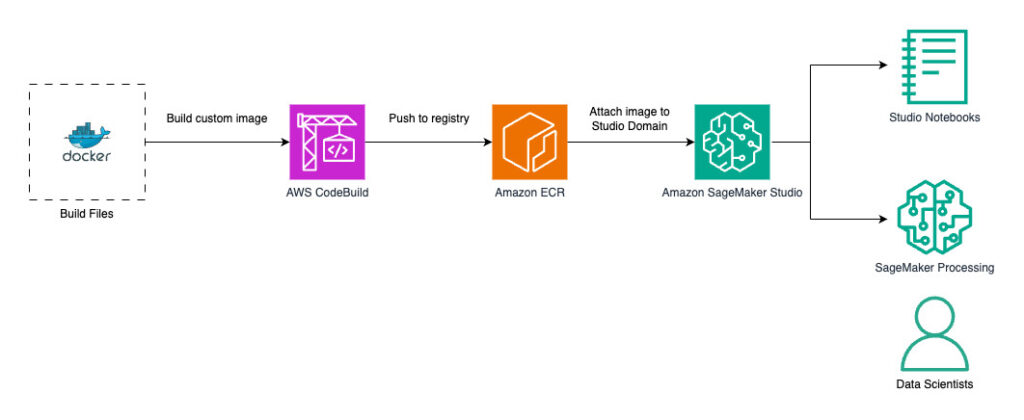
Ingestion flow
The ingestion flow prepares and stores the necessary data for the AI agent to access. The following diagram illustrates how it works.
The workflow includes the following steps:
Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
Amazon Bedrock Knowledge Bases ingests these documents:
The knowledge base is configured to use the S3 bucket as a data source.
The data source is synchronized and the knowledge base detects new, modified, or deleted documents in the S3 bucket and updates accordingly.
The documents are chunked into smaller segments for more effective processing. This solution uses fixed-size chunking, where you can configure the desired chunk size by specifying the number of tokens per chunk and an overlap percentage.
Each chunk is embedded by using an embedding model such as Cohere Embed on Amazon Bedrock to create vector representations (embeddings) of the text.
The embeddings are stored in the Amazon OpenSearch Service owner manuals index. OpenSearch Service is used as the vector store for efficient similarity searching. The embeddings, along with metadata about the source documents, are indexed for quick retrieval.
User interaction flow
The following diagram illustrates the user interaction flow.
A user interacts with the Car Parts Agent through a web application interface. They can ask questions like “What wiper blades fit a 2021 Honda CR-V?” or ”Tell me about part number 76622-T0A-A01.”
The web application sends the user’s query to the Amazon Bedrock agent using the InvokeAgent API. The agent, using Anthropic’s Claude 3 Sonnet, interprets the user’s query and determines the best course of action through chain-of-thought (CoT) reasoning. At this stage, the agent employs guardrails to make sure it stays within its defined scope and capabilities. Through a runtime process that includes preprocessing and postprocessing steps, the agent categorizes the user’s input. This allows it to handle out-of-scope questions or potentially harmful inputs appropriately, without attempting to answer beyond its capabilities or knowledge base. The agent then analyzes the query to extract key information such as vehicle details, part numbers, or general automotive topics. If the query is within scope, the agent proceeds; if not, it provides a response indicating it can’t assist with that particular request.
For general inquiries, the agent consults its knowledge base in Amazon Bedrock, which includes information from various car manuals. This allows the agent to provide context and general information about car parts and systems.
For specific part inquiries, the agent consults the action groups available to the agent and invokes the correct action (API) to retrieve relevant information. This invocation happens when the agent determines that it needs to run a specific action based on the user input.
The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information. It can access the inventory index for specific part details or the compatible parts index for compatibility information.
The Lambda function processes the OpenSearch Service results and formats them for the Amazon Bedrock agent.
The Amazon Bedrock agent takes the formatted results and generates a human-readable response, combining database information with its general knowledge to provide comprehensive answers.
The following diagram illustrates the workflow of the agent.
This diagram illustrates the agent’s workflow from user query to response generation, integrating knowledge base and API data to provide comprehensive answers and handle follow-up questions.
Developer tools
The solution also uses the following developer tools:
AWS Powertools for Lambda – This is a suite of utilities for Lambda functions that generates OpenAPI schemas from your Lambda function code. It provides annotations for business logic, descriptions, and parameter validations, automatically producing JSON-serialized OpenAPI schemas for use with Amazon Bedrock Agents.
AWS Generative AI Constructs Library – This is an open source extension of the AWS Cloud Development Kit (AWS CDK) that offers multi-service, well-architected patterns for quickly defining generative AI solutions. It provides constructs to help developers build generative AI applications using pattern-based definitions for your infrastructure.
Prerequisites
You should have the following prerequisites:
An AWS account with the appropriate AWS Identity and Access Management (IAM) permissions to create Amazon Bedrock agents and knowledge bases, Lambda functions, and IAM roles
Access to the following models hosted on Amazon Bedrock:
Anthropic’s Claude 3 Sonnet (model ID: anthropic.claude-3-sonnet-20240229-v1:0)
Cohere Embed English v3 (model ID: cohere.embed-english-v3)
A local development environment with the following:
The AWS Command Line Interface (AWS CLI) installed and configured with appropriate permissions.
Python 3.9 or later
Node.js v20.x or later
The AWS CDK CLI installed
Deploy the solution
The following steps outline the process to deploying the solution using the AWS CDK. The complete source code for this solution is available in the GitHub repository.
Open your terminal and run the following commands to clone the GitHub repository to your local machine: git clone https://github.com/aws-samples/bedrock-agent-carpart-lookup.git
cd bedrock-agent-carpart-lookup
Create and activate a Python virtual environment: python -m venv .venv
source .venv/bin/activate # On Windows, use .venvScriptsactivate
Install the required Python packages: pip install -r requirements.txt
Use the AWS CDK CLI to deploy the solution: cdk deploy
During deployment, you may be prompted to approve IAM role creations and security changes. Review and approve these if you’re comfortable with the permissions. After deployment, the AWS CDK CLI will output the web application URL. Make note of this URL (as shown in following screenshot) to access and test the agent.
After you deploy the solution, you can verify the created resources on the Amazon Bedrock console. On the Agents page, you’ll notice a new agent called car-parts-agent.
Effective agent instructions are crucial for optimizing the performance of AI-powered assistants. A well-structured set of instructions should encompass several key components:
Agent role – Define the assistant’s purpose, such as serving as a Car Parts Assistant that helps users find compatible parts and automotive information
Agent actions – Outline primary tasks, such as identifying parts based on vehicle details, verifying compatibility, and providing technical specifications
Agent guidelines – Establish rules for interaction, prioritizing accuracy and safety, clearly stating uncertainties, and using actions for searches
Agent guardrails – Implement limits to make sure the agent operates safely and effectively, using relevant automotive knowledge to enhance user support
For example, the agent we deployed has been preconfigured with the following instruction:
You are an Car Parts Assistant, helping users find compatible parts and providing automotive information. Your main tasks are: Part Identification: Find specific parts based on vehicle details (make, model, year). Assist with partial information. Compatibility Checks: Verify if parts are compatible with given vehicles. Technical Info: Provide part specifications, features, and explain component functions. Use database functions for searches and compatibility checks. Supplement with automotive knowledge for comprehensive help. Your goal is to assist effectively while ensuring users make informed decisions about their vehicle parts. Always prioritize accuracy and safety. State uncertainties clearly.
□ Role
□ Actions
□ Guidelines
□ Guardrails
The agent has two main components:
Action group – An action group named CarpartsApi is created, and the actions it can perform are defined using an OpenAPI schema. Optionally, you can use Powertools for AWS Lambda to simplify the process of generating the OpenAPI schema. For more information, refer to the PowerTools documentation on Amazon Bedrock Agents. The OpenAPI schema used by this agent can be viewed on the following GitHub repo. The action group is then associated with a Lambda function containing the business logic for these actions.
Knowledge base – This repository enhances the agent’s responses using RAG in Amazon Bedrock. It contains information from car manuals and technical documentation. When associating a knowledge base with an agent, you can optionally provide a description on how the agent can use the knowledge base. For this demo, we use the following description for the knowledge base:
This knowledge base contains manuals and technical documentation about various car makes from manufacturers such as Honda, Tesla, Ford, Subaru, Kia, Toyota etc.
□ Instructions
The agent employs CoT reasoning to process user queries, analyzing input against its instructions and evaluating actions based the OpenAPI provided and knowledge base description. When required information is missing, as determined by the OpenAPI schema’s specifications, the agent formulates questions to elicit necessary data from the user. This analysis and information gathering leads to a logical sequence of steps, including API calls and knowledge base queries. The resulting observation enhances the prompt for the FM, which then determines and runs the most effective actions.
For this post, we use the AWS CDK and the AWS Generative AI Constructs Library to create the Amazon Bedrock agent. This approach enables version-controlled, reproducible infrastructure as code (IaC). Alternatively, you can create agents using the AWS CLI or AWS Management Console. For more details, see create and configure agent manually.
Test and validate the solution
After you deploy the solution, you can test the agent either on the Amazon Bedrock console or through the application URL noted earlier. In the application, you can ask questions like “What wiper blades fit a 2021 Honda CR-V?” or “Tell me about part number 76622-T0A-A01.”
To illustrate the Amazon Bedrock agent’s reasoning capabilities, let’s examine the agent’s response to a user question “What wiper blades fit a 2021 Honda CR-V?” The workflow would consist of the following steps:
The agent analyzes the query, identifying key elements: Honda (make), CR-V (model), 2021 (year), and wiper blades (part category).
It then reasons about which API to use, selecting the get_compatible_parts function as the most appropriate for vehicle-specific part queries.
The agent maps the query elements to the function’s parameters, demonstrating its understanding of how to translate natural language to API calls.
The agent calls the carPartsApi/get_compatible_parts action, which queries the OpenSearch Service index for compatible parts. When an action group using a Lambda function is invoked, Amazon Bedrock sends a Lambda input event using a general format.
Upon receiving a response, the agent interprets the data, identifying relevant wiper blade options. The agent formulates a natural language response, recommending specific wiper blades. Similarly, Amazon Bedrock expects a response from your Lambda function to match a pre-defined format.
We get the following natural language response:
Based on the compatible parts search for a 2021 Honda CR-V in the “Wipers” category, here are the recommended wiper blade options:
Wiper Blade Set (Part #76622-TLA-A11) – This is a genuine Honda wiper blade set that includes the driver and passenger side wiper blades for the CR-V.
Rear Wiper Blade (Part #76630-TLA-A01) – This is the rear wiper blade specifically for the 2021 CR-V.
You can also consider individual wiper blades like the Driver Side Wiper Blade (Part #76622-T0A-A01) or the Passenger Side Wiper Arm (Part #76630-T0A-A01) if you only need to replace one side.
This process showcases how Amazon Bedrock agents can intelligently integrate enterprise data APIs with AI-driven reasoning to provide accurate, context-aware responses to customer queries.
Clean up
To avoid future costs and clean up resources after you’re done exploring the solution, delete the resources you created by running the following command from your terminal (from the project directory):
cdk destroy
Key considerations
When implementing Amazon Bedrock Agents, consider the following factors to facilitate optimal performance and scalability:
Agent design – Follow these recommendations when designing your agent:
Keep instructions focused and clear, with specific responsibilities for the agent
For complex use cases, consider multiple specialized agents rather than overloading a single one
Explore different FMs to find the best fit for your needs, considering both behavior and cost
Action management – Consider the following recommendations for action management:
Define actions carefully, including only those that the agent should reliably perform
Use clear, descriptive names for actions to help the agent determine their relevance
Avoid overlapping actions to prevent confusion and conflicts during operation
Testing – Make sure your testing includes the following steps:
Establish clear testing protocols
Identify common use case inputs and set accuracy targets
Define edge case inputs and agree on acceptable accuracy levels
Determine out-of-domain inputs where the agent should not respond
Automate tests and run them with system changes to verify consistency and reliability
Performance optimization – Consider the following performance optimizations:
Break down complex operations into smaller actions to enhance response time and error handling
Implement a “fail fast” principle for invalid queries, allowing more time for complex tasks
Security and compliance – Use Amazon Bedrock Guardrails to prevent the agent from generating harmful content or making unauthorized actions
Cost management – Monitor usage-based pricing for token processing and storage, facilitating efficient resource allocation and cost management
Conclusion
Integrating enterprise data APIs with Amazon Bedrock Agents offers a powerful solution for streamlining customer support, as demonstrated in the automotive parts industry. This AI-driven approach enables rapid, accurate responses to complex queries, seamlessly integrates multiple data sources, and reduces staff workload while enhancing customer experience through context-aware interactions.
The solution discussed in this post can elevate customer support across various industries. By using Amazon Bedrock agents, organizations can create more efficient, accurate, and satisfying support experiences tailored to their specific needs. To explore how AI agents can transform your own support operations, refer to Automate tasks in your application using conversational agents.
About the Authors
Deepak Kovvuri is a Senior Solutions Architect supporting Automotive and Manufacturing Customers at AWS in the US Northeast. He has over 6 years of experience in helping customers architecting a DevOps strategy for their cloud workloads. Deepak specializes in CI/CD, Systems Administration, Infrastructure as Code and Container Services. He holds an Masters in Computer Engineering from University of Illinois at Chicago.
Kingston Bosco is a Senior Solutions Architect for Global Strategic Partners at AWS. He designs and implements solutions that optimize DevOps workflows, automate cloud operations, and improve infrastructure management for customers. He holds a Master’s in Information Systems. In his free time, he enjoys hiking with his dogs and playing soccer.

{kind=link}
{kind=link}