Amazon SageMaker Studio provides a comprehensive suite of fully managed integrated development environments (IDEs) for machine learning (ML), including JupyterLab, Code Editor (based on Code-OSS), and RStudio. It supports all stages of ML development—from data preparation to deployment, and allows you to launch a preconfigured JupyterLab IDE for efficient coding within seconds. Additionally, its flexible interface and artificial intelligence (AI) powered coding assistant simplifies and enhances the ML workflow configuration, debugging, and code testing.
Geospatial data such as satellite images, coordinate traces, or aerial maps that are enriched with characteristics or attributes of other business and environmental datasets is becoming increasingly available. This unlocks valuable use cases in fields such as environmental monitoring, urban planning, agriculture, disaster response, transportation, and public health.
To effectively utilize the wealth of information contained in such datasets for ML and analytics, access to the right tools for geospatial data handling is crucial. This is especially relevant given that geospatial data often comes in specialized file formats such as Cloud Optimized GeoTIFF (COG), Zarr files, GeoJSON, and GeoParquet that require dedicated software tools and libraries to work with.
To address these specific needs within SageMaker Studio, this post shows you how to extend Amazon SageMaker Distribution with additional dependencies to create a custom container image tailored for geospatial analysis. Although the example in this post focuses on geospatial data science, the methodology presented can be applied to any kind of custom image based on SageMaker Distribution.
SageMaker Distribution images are Docker images that come with preinstalled data science packages and are preconfigured with a JupyterLab IDE, which allows you to use these images in the SageMaker Studio UI as well as for non-interactive workflows like processing or training. This allows you to use the same runtime across SageMaker Studio notebooks and asynchronous jobs like processing or training, facilitating a seamless transition from local experimentation to batch execution while only having to maintain a single Docker image.
In this post, we provide step-by-step guidance on how you can build and use custom container images in SageMaker Studio. Specifically, we demonstrate how you can customize SageMaker Distribution for geospatial workflows by extending it with open-source geospatial Python libraries. We explain how to build and deploy the image on AWS using continuous integration and delivery (CI/CD) tools and how to make the deployed image accessible in SageMaker Studio. All code used in this post, including the Dockerfile and infrastructure as code (IaC) templates for quick deployment, is available as a GitHub repository.
Solution overview
You can building a custom container image and use it in SageMaker Studio with the following steps:
Create a Dockerfile that includes the additional Python libraries and tools.
Build a custom container image from the Dockerfile.
Push the custom container image to a private repository on Amazon Elastic Container Registry (Amazon ECR).
Attach the image to your Amazon SageMaker Studio domain.
Access the image from your JupyterLab space.
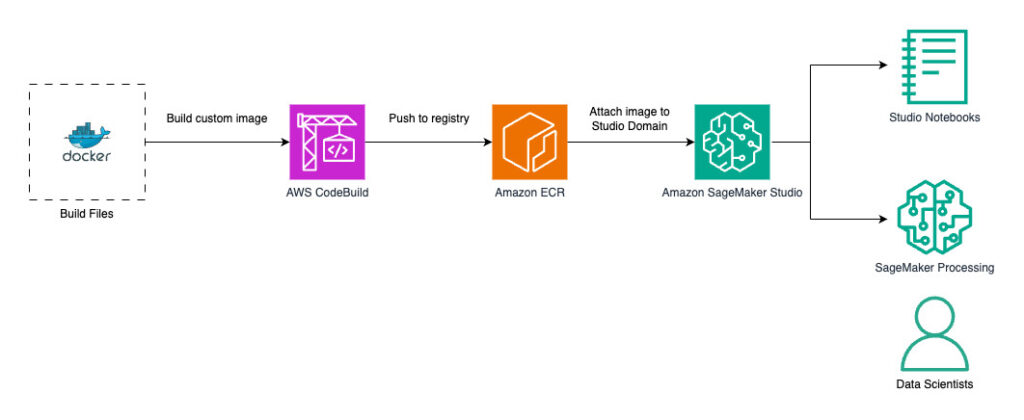
The following diagram illustrates the solution architecture.
The solution uses AWS CodeBuild, a fully managed service that compiles source code and produces deployable software artifacts, to build a new container image from a Dockerfile. CodeBuild supports a broad selection of git version control sources like AWS CodeCommit, GitHub, and GitLab. For this post, we host our build files on Amazon Simple Storage Service (Amazon S3) and use it as the source provider for the CodeBuild project. You can extend this solution to work with alternative CI/CD tooling, including GitLab, Jenkins, Harness, or other tools.
CodeBuild retrieves the build files from Amazon S3, runs a Docker build, and pushes the resulting container image to a private ECR repository. Amazon ECR is a managed container registry that facilitates the storage, management, and deployment of container images.
The custom image is then attached to a SageMaker Studio domain and can be used by data scientists and data engineers as an IDE or as runtime for SageMaker processing or training jobs.
Prerequisites
This post covers the default approach for SageMaker Studio, which involves a managed network interface that allows internet communication. We also include steps to adapt this for use within a private virtual private cloud (VPC).
Before you get started, verify that you have the following prerequisites:
SageMaker Studio V2 – Make sure that you’re using the most current version of your SageMaker Studio domain and user profiles. If you’re currently using SageMaker Studio Classic, refer to Migrating from Amazon SageMaker Studio Classic. To create a new domain, see Quick setup to Amazon SageMaker.
Correct IAM permissions – You need to make sure that the AWS Identity and Access Management (IAM) role used has the correct permissions to run the build in CodeBuild, create a repository in Amazon ECR, and push images to that repository. For more details, refer to Using the Amazon SageMaker Studio Image Build CLI to build container images from your Studio notebooks. If you choose to deploy this solution using the provided IaC sample, these permissions will be set automatically.
If you intend to follow this post and deploy the CodeBuild project and the ECR repository using IaC, you also need to install the AWS Cloud Development Kit (AWS CDK) on your local machine. For instructions, see Getting started with the AWS CDK. If you’re using a cloud-based IDE like AWS Cloud9, the AWS CDK will usually come preinstalled.
If you want to securely deploy your custom container using your private VPC, you also need the following:
A VPC with a private subnet
VPC endpoints for the following services:
Amazon S3
SageMaker
Amazon ECR
AWS Security Token Service (AWS STS)
CodeBuild for building Docker containers
To set up a SageMaker Studio domain with a private VPC, see Connect Studio notebooks in a VPC to external resources.
Extend SageMaker Distribution
By default, SageMaker Studio provides a selection of curated pre-built Docker images as part of SageMaker Distribution. These images include popular frameworks for ML, data science, and visualization, including deep learning frameworks like PyTorch, TensorFlow and Keras; popular Python packages like NumPy, scikit-learn, and pandas; and IDEs like JupyterLab and Code Editor. All installed libraries and packages are mutually compatible and are provided with their latest compatible versions. Each distribution version is available in two variants, CPU and GPU, and is hosted on the Amazon ECR Public Gallery. To be able to work with geospatial data in SageMaker Studio, you need to extend SageMaker Distribution by adding the required geospatial libraries like gdal, geospandas, leafmap, or rioxarray and make it accessible to users through SageMaker Studio.
Let’s first review how to extend SageMaker Distribution for geospatial analyses and ML. To do so, we largely follow the provided template for creating custom Docker files in SageMaker, with a few subtle but important differences specific to the geospatial libraries we want to install. The full Dockerfile is as follows:
Let’s break down the key geospatial-specific modifications.
First, you install the Geospatial Data Abstraction Library (GDAL) on Linux. GDAL is an open source library that provides drivers for reading and writing raster and vector geospatial data formats. It provides the backbone for many open source and proprietary GIS applications, including the libraries used in the post. This is implemented as follows (see see Install GDAL for Python for more details for more details):
Now that you have created your custom geospatial Dockerfile, you can build it and push the image to Amazon ECR.
Build a custom geospatial image
To build the Docker image, you need a build environment equipped with Docker and the AWS Command Line Interface (AWS CLI). This environment can be set up on your local machine, in a cloud-based IDE like AWS Cloud9, or as part of a continuous integration service like CodeBuild.
Before you build the Docker image, identify the ECR repository where you will push the image. Your image must be tagged in the following format: <your-aws-account-id>.dkr.ecr.<your-aws-region>.amazonaws.com/<your-repository-name>:<tag>. Without this tag, pushing it to an ECR repository is not possible. If you’re deploying the solution using the AWS CDK, an ECR repository is automatically created, and a CodeBuild project is configured to use this repository as the target for pushing the image. When you initiate the CodeBuild build, the image is built, tagged, and then pushed to the previously created ECR repository.
The following steps are applicable only if you choose to perform these actions manually.
To build the image manually, run the following command in the same directory as the Dockerfile:
After building your image, you must log in to the ECR repository with this command before pushing the image:
Next, push your Docker image using the following command:
Your image has now been pushed to the ECR repository and you can proceed to attach it to SageMaker.
Attach the custom geospatial image to SageMaker Studio
After your custom image has been successfully pushed to Amazon ECR, you need to attach it to a SageMaker domain to be able to use it within SageMaker Studio.
On the SageMaker console, choose Domains under Admin configurations in the navigation pane.
If you don’t have a SageMaker domain set up yet, you can create one.
From the list of available domains, choose the domain to which you want to attach the geospatial image.
On the Domain details page, choose the Environment tab
In Custom images for personal Studio apps section, choose Attach image.
Choose New image and enter the ECR image URI from the build pipeline output. This should have the following format <your-aws-account-id>.dkr.ecr.<your-aws-region>.amazonaws.com/<your-repository-name>:<tag>
Choose Next.
For Image name, enter a custom image name (for this post, we use custom-geospatial-sm-dist).
For Image display name, enter a custom display name (for this post, we use Geospatial SageMaker Distribution (CPU)).
For Description, enter an image description.
Choose JupyterLab image as the application type and choose Submit.
When returning to the Environment tab on the Domain details page, you should now see your image listed under Custom images for personal Studio apps.
Attach the custom geospatial image using the AWS CLI
You can also automate the process using the AWS CLI.
First, register the image in SageMaker and create an image version:
Next, create a file containing the following content. You can add multiple custom images by adding additional entries to the CustomImages list.
The next step assumes that you named the file from the previous step default-user-settings.json. The following command attaches the SageMaker image to the specified Studio domain:
Use the custom geospatial Image in the JupyterLab app
In the previous section, we demonstrated how to attach the image to a SageMaker domain. When you create a new (or modify an existing) JupyterLab space inside this domain, the newly created custom image will now be available. You can choose it on the Image dropdown menu, where it now appears alongside the default AWS curated SageMaker Distribution image versions under Custom.
To run a space using the custom geospatial image, choose Geospatial SageMaker Distribution (CPU) as your image, then choose Run space.
After the space has been provisioned and is in Running state, choose Open JupyterLab. This will bring up the JupyterLab IDE in a new browser tab. Select a notebook with Python3 (ipykernel) to start up a new Jupyter notebook running on top of the custom geospatial image.
Run interactive geospatial data analyses and large-scale processing jobs in SageMaker
After you build the custom geospatial image and attach it to your SageMaker domain, you can use it in one of two main ways:
You can use the image as the base to run a JupyterLab notebook kernel to perform in-notebook interactive development and geospatial analytics.
You can use the image in a SageMaker processing job to run highly parallelized geospatial processing pipelines. Reusing the interactive kernel image for asynchronous batch processing can be advantageous because only a single image will have to maintained and routines developed in an interactive manner using a notebook can be expected to work seamlessly in the processing job. If startup latency caused by longer image load times is a concern, you can choose to build a dedicated more lightweight image just for processing (see Build Your Own Processing Container for details).
For hands-on examples of both approaches, refer to the accompanying GitHub repository.
In-notebook interactive development using a custom image
After you choose the custom geospatial image as the base image for your JupyterLab space, SageMaker provides you with access to many geospatial libraries that can now be imported without the need for additional installs. For example, you can run the following code to initialize a geometry object and plot it on a map within the familiar environment of a notebook:
import shapely
import leafmap
import geopandas
coords = [[-102.00723310488662,40.596123257503024],[-102.00723310488662,40.58168585757733],[-101.9882214495914,40.58168585757733],[-101.9882214495914,40.596123257503024],[-102.00723310488662,40.596123257503024]]
polgyon = shapely.Polygon(coords)
gdf = geopandas.GeoDataFrame(index=[0], crs=’epsg:4326′, geometry=[polgyon])
Map = leafmap.Map(center=[40.596123257503024, -102.00723310488662], zoom=13)
Map.add_basemap(“USGS NAIP Imagery”)
Map.add_gdf(gdf, layer_name=”test”, style={“color”: “yellow”, “fillOpacity”: 0.3, “clickable”: True,})
Map
Highly parallelized geospatial processing pipelines using a SageMaker processing job and a custom image
You can specify the custom image as the image to run a SageMaker processing job. This enables you to use specialist geospatial processing frameworks to run large-scale distributed data processing pipelines with just a few lines of code. The following code snippet initializes and then runs a SageMaker ScriptProcessor object that uses the custom geospatial image (specified using the geospatial_image_uri variable) to run a geospatial processing routine (specified in a processing script) on 20 ml.m5.2xlarge instances:
import sagemaker
from sagemaker import get_execution_role
from sagemaker.sklearn.processing import ScriptProcessor
from sagemaker.processing import ProcessingInput, ProcessingOutput
region = sagemaker.Session().boto_region_name
role = get_execution_role()
geospatial_image_uri = “<GEOSPATIAL-IMAGE-URI>” #<– set to uri of the custom geospatial image
processor_geospatial_data_cube = ScriptProcessor(
command=[‘python3’],
image_uri=geospatial_image_uri,
role=role,
instance_count=20,
instance_type=’ml.m5.2xlarge’,
base_job_name=’aoi-data-cube’
)
processor_geospatial_data_cube.run(
code=’scripts/generate_aoi_data_cube.py’, #<– processing script
inputs=[
ProcessingInput(
source=f”s3://{bucket_name}/{bucket_prefix_aoi_meta}/”,
destination=’/opt/ml/processing/input/aoi_meta/’, #<– meta data (incl. geography) of the area of observation
s3_data_distribution_type=”FullyReplicated” #<– sharding strategy for distribution across nodes
),
ProcessingInput(
source=f”s3://{bucket_name}/{bucket_prefix_sentinel2_meta}/”,
destination=’/opt/ml/processing/input/sentinel2_meta/’, #<– Sentinel-2 scene metadata (1 file per scene)
s3_data_distribution_type=”ShardedByS3Key” #<– sharding strategy for distribution across nodes
),
],
outputs=[
ProcessingOutput(
source=’/opt/ml/processing/output/’,
destination=f”s3://{bucket_name}/processing/geospatial-data-cube/{execution_id}/output/” #<– output S3 path
)
]
)
A typical processing routine involving raster file loading, clipping to an area of observation, resampling specific bands, and masking clouds among other steps across 134 110x110km Sentinel-2 scenes completes in under 15 minutes, as can be seen in the following Amazon CloudWatch dashboard.
Clean up
After you’re done running the notebook, don’t forget to stop the SageMaker Studio JupyterLab application to avoid incurring unnecessary costs. If you deployed the additional infrastructure using the AWS CDK, you can delete the deployed stack by running the following command in your local code checkout:
Conclusion
This post has equipped you with the knowledge and tools to build and use custom container images tailored for geospatial analysis in SageMaker Studio. By extending SageMaker Distribution with specialized geospatial libraries, you can customize your environment for specialized use cases. This empowers you to unlock the vast potential of geospatial data for applications such as environmental monitoring, urban planning, and precision agriculture—all within the familiar and user-friendly environment of SageMaker Studio.
Although this post focused on geospatial workflows, the methodology presented is broadly applicable. You can utilize the same principles to tailor container images for any domain requiring specific libraries or tools beyond the scope of SageMaker Distribution. This empowers you to create a truly customized development experience within SageMaker Studio, catering to your unique project needs.
The provided resources, including sample code and IaC templates, offer a solid foundation for building your own custom images. Experiment and explore how this approach can streamline your ML workflows involving geospatial data or any other specialized domain. To get started, visit the accompanying GitHub repository.
About the Authors
Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions and building ML platforms on AWS. His expertise spans machine learning, data engineering, and scalable distributed systems, augmented by a strong background in software engineering and industry expertise in domains such as autonomous driving.
Dr. Karsten Schroer is a Senior Machine Learning (ML) Prototyping Architect at AWS, focused on helping customers leverage artificial intelligence (AI), ML, and generative AI technologies. With deep ML expertise, he collaborates with companies across industries to design and implement data- and AI-driven solutions that generate business value. Karsten holds a PhD in applied ML.
Anirudh Viswanathan is a Senior Product Manager, Technical, at AWS with the SageMaker team, where he focuses on Machine Learning. He holds a Master’s in Robotics from Carnegie Mellon University and an MBA from the Wharton School of Business. Anirudh is a named inventor on more than 50 AI/ML patents. He enjoys long-distance running, exploring art galleries, and attending Broadway shows.