We are excited to announce the availability of Cohere’s advanced reranking model Rerank 3.5 through our new Rerank API in Amazon Bedrock. This powerful reranking model enables AWS customers to significantly improve their search relevance and content ranking capabilities. This model is also available for Amazon Bedrock Knowledge Base users. By incorporating Cohere’s Rerank 3.5 in Amazon Bedrock, we’re making enterprise-grade search technology more accessible and empowering organizations to enhance their information retrieval systems with minimal infrastructure management.
In this post, we discuss the need for Reranking, the capabilities of Cohere’s Rerank 3.5, and how to get started using it on Amazon Bedrock.
Reranking for advanced retrieval
Reranking is a vital enhancement to Retrieval Augmented Generation (RAG) systems that adds a sophisticated second layer of analysis to improve search result relevance beyond what traditional vector search can achieve. Unlike embedding models that rely on pre-computed static vectors, rerankers perform dynamic query-time analysis of document relevance, enabling more nuanced and contextual matching. This capability allows RAG systems to effectively balance between broad document retrieval and precise context selection, ultimately leading to more accurate and reliable outputs from language models while reducing the likelihood of hallucinations.
Existing search systems significantly benefit from reranking technology by providing more contextually relevant results that directly impact user satisfaction and business outcomes. Unlike traditional keyword matching or basic vector search, reranking performs an intelligent second-pass analysis that considers multiple factors, including semantic meaning, user intent, and business rules to optimize search result ordering. In ecommerce specifically, reranking helps surface the most relevant products by understanding nuanced relationships between search queries and product attributes, while also incorporating crucial business metrics like conversion rates and inventory levels. This advanced relevance optimization leads to improved product discovery, higher conversion rates, and enhanced customer satisfaction across digital commerce platforms, making reranking an essential component for any modern enterprise search infrastructure.
Introducing Cohere Rerank 3.5
Cohere’s Rerank 3.5 is designed to enhance search and RAG systems. This intelligent cross-encoding model takes a query and a list of potentially relevant documents as input, then returns the documents sorted by semantic similarity to the query. Cohere Rerank 3.5 excels in understanding complex information requiring reasoning and is able to understand the meaning behind enterprise data and user questions. Its ability to comprehend and analyze enterprise data and user questions across over 100 languages including Arabic, Chinese, English, French, German, Hindi, Japanese, Korean, Portuguese, Russian, and Spanish, makes it particularly valuable for global organizations in sectors such as finance, healthcare, hospitality, energy, government, and manufacturing.
One of the key advantages of Cohere Rerank 3.5 is its ease of implementation. Through a single Rerank API call in Amazon Bedrock, you can integrate Rerank into existing systems at scale, whether keyword-based or semantic. Reranking strictly improves first-stage retrievals on standard text retrieval benchmarks.
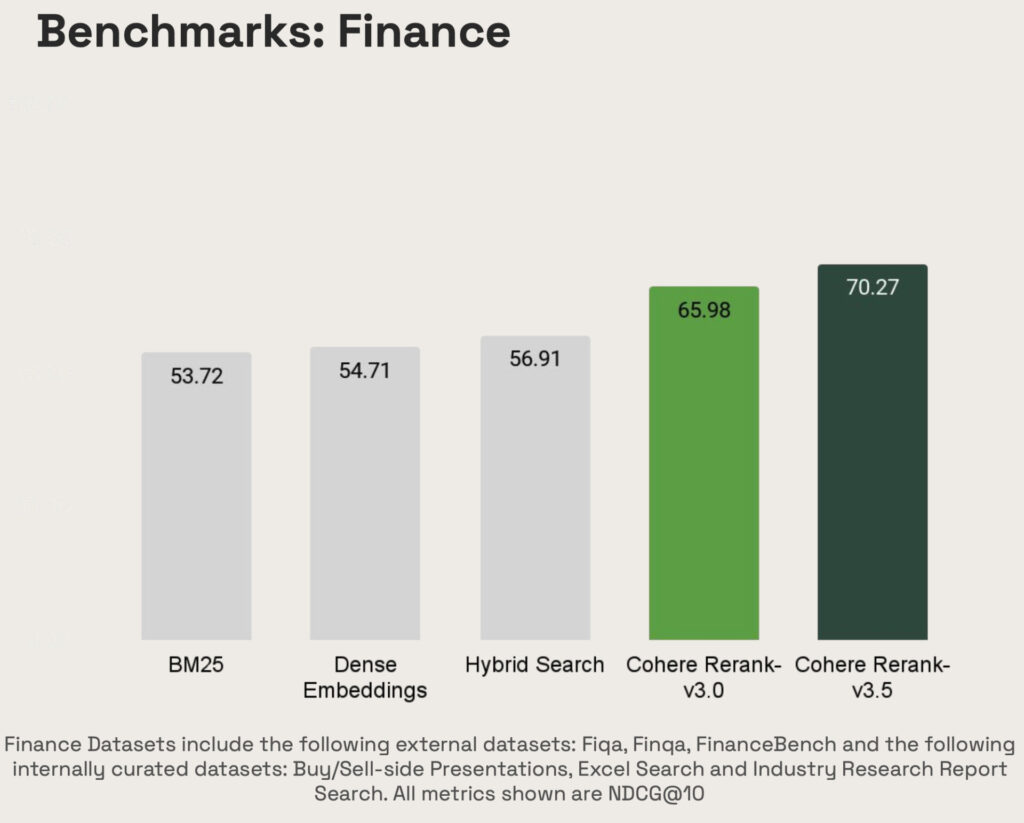
Cohere Rerank 3.5 is state of the art in the financial domain, as illustrated in the following figure.
Cohere Rerank 3.5 is also state of the art in the ecommerce domain, as illustrated in the following figure. Cohere’s ecommerce benchmarks revolve around retrieval on various products, including fashion, electronics, food, and more.
Products were structured as strings in a key-value pair format such as the following:
Cohere Rerank 3.5 also excels in hospitality, as shown in the following figure. Hospitality benchmarks revolve around retrieval on hospitality experiences and lodging options.
Documents were structured as strings in a key-value pairs format such as the following:
We see noticeable gains in project management performance across all types of issue tracking tasks, as illustrated in the following figure.
Cohere’s project management benchmarks span a variety of retrieval tasks, such as:
Search through engineering tickets from various project management and issue tracking software tools
Search through GitHub issues on popular open source repos
Get started with Cohere Rerank 3.5
To start using Cohere Rerank 3.5 with Rerank API and Amazon Bedrock Knowledge Bases, navigate to the Amazon Bedrock console, and click on Model Access on the left hand pane. Click on Modify Access, select Cohere Rerank 3.5, click Next and hit submit.
Get Started with Amazon Bedrock Rerank API
The Cohere Rerank 3.5 model, powered by the Amazon Bedrock Rerank API, allows you to rerank input documents directly based on their semantic relevance to a user query – without requiring a pre-configured knowledge base. The flexibility makes it a powerful tool for various use cases.
To begin, set up your environment by importing the necessary libraries and initializing Boto3 clients:
Next, define a main function that reorders a list of text documents by computing relevance scores based on the user query:
For instance, imagine a scenario where you need to identify emails related to returning items from a multilingual dataset. The example below demonstrates this process:
Now, prepare the list of text sources that will be passed into the rerank_text() function:
You can then invoke rerank_text() by specifying the user query, the text resources, the desired number of top-ranked results, and the model ARN:
The output generated by the Amazon Bedrock Rerank API with Cohere Rerank 3.5 for this query is:
The relevance scores provided by the API are normalized to a range of [0, 1], with higher scores indicating higher relevance to the query. Here the 5th item in the list of documents is the most relevant. (Translated from German to English: Hello, I have a question about my last order. I received the wrong item and need to return it.)
You can also get started using Cohere Rerank 3.5 with Amazon Bedrock Knowledge Bases by completing the following steps:
In the Amazon Bedrock console, choose Knowledge bases under Builder tools in the navigation pane.
Choose Create knowledge base.
Provide your knowledge base details, such as name, permissions, and data source.
To configure your data source, specify the location of your data.
Select an embedding model to convert the data into vector embeddings, and have Amazon Bedrock create a vector store in your account to store the vector data.
When you select this option (available only in the Amazon Bedrock console), Amazon Bedrock creates a vector index in Amazon OpenSearch Serverless (by default) in your account, removing the need to manage anything yourself.
Review your settings and create your knowledge base.
In the Amazon Bedrock console, choose your knowledge base and choose Test knowledge base.
Choose the icon for additional configuration options for testing your knowledge base.
Choose your model (for this post, Cohere Rerank 3.5) and choose Apply.
The configuration pane shows the new Reranking section menu with additional configuration options. The number of reranked source chunks returns the specified number of highest relevant chunks.
Conclusion
In this post, we explored how to use Cohere’s Rerank 3.5 model in Amazon Bedrock, demonstrating its powerful capabilities for enhancing search relevance and robust reranking capabilities for enterprise applications, enhancing user experience and optimizing information retrieval workflows. Start improving your search relevance today with Cohere’s Rerank model on Amazon Bedrock.
Cohere Rerank 3.5 in Amazon Bedrock is available in the following AWS Regions: in us-west-2 (US West – Oregon), ca-central-1 (Canada – Central), eu-central-1 (Europe – Frankfurt), and ap-northeast-1 (Asia Pacific – Tokyo).
Share your feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
To learn more about Cohere Rerank 3.5’s features and capabilities, view the Cohere in Amazon Bedrock product page.
About the Authors
Karan Singh is a Generative AI Specialist for third-party models at AWS, where he works with top-tier third-party foundation model (FM) providers to develop and execute joint Go-To-Market strategies, enabling customers to effectively train, deploy, and scale FMs to solve industry specific challenges. Karan holds a Bachelor of Science in Electrical and Instrumentation Engineering from Manipal University, a master’s in science in Electrical Engineering from Northwestern University and is currently an MBA Candidate at the Haas School of Business at University of California, Berkeley.
James Yi is a Senior AI/ML Partner Solutions Architect at Amazon Web Services. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in generative AI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.