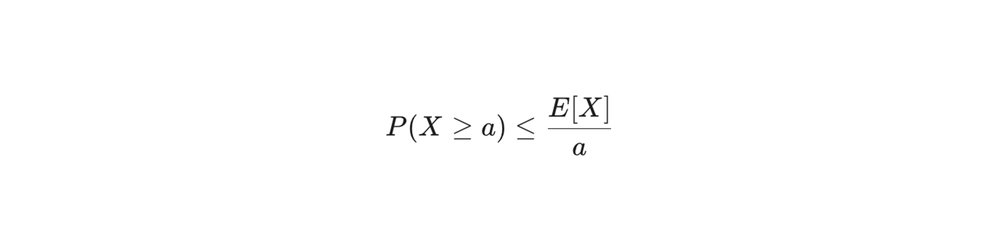
Frontier AI models have redefined the unit of compute. At trillion-parameter scale, AI training requires thousands of interconnected components, orchestrated in industrial-scale deployments to operate as a single, massive entity.
Likewise, when it comes to reliability, aggregate infrastructure availability is what matters. Yet for almost two decades, instance-level reliability has been the cloud standard. Designed for microservices and horizontally scalable applications, instance-level reliability treats infrastructure as a collection of small independent units. This model is fundamentally inadequate for large-scale AI workloads.
We believe reliability must shift from an instance- to a cluster-level model.
For over a decade, Google has operated Tensor Processing Unit (TPU) clusters at scale, achieving reliability that meets the architectural requirements of modern AI workloads. In this blog, we’re presenting our cluster-level reliability framework for Google Cloud TPUs that focuses on collective performance at the superpod level, and one we use internally within Google to build the world’s most advanced AI models. This framework is the operational standard for TPUs in production today, and serves as the architectural blueprint for our recently announced eighth-generation TPUs.
Reliability for AI supercomputers
TPU superpods consist of thousands of chips arranged into cubes (64 TPUs), with high-speed Inter-Chip Interconnect (ICI) links connecting every chip within a cube and a dynamically configurable Optical Circuit Switch (OCS) network connecting all cubes to form a superpod.
For system-wide training progress, we must maximize the number of fully healthy cubes within a superpod. Because the performance of AI models relies on high-bandwidth, low-latency communication, every chip and ICI link within a cube must be operational for that unit to contribute to the training progress. Driven by these architectural realities, our cluster-level framework helps define how the industry can achieve reliability in the AI era, moving from instance-level reliability to availability of scale.
Deep dive: The mathematics of availability at scale
Instance-level reliability models are often deterministic, but industrial-scale AI deployments require a probabilistic approach over thousands of chips. In a traditional setup, you might track the Mean Time Between Failures (MTBF) of a single chip. However, at the scale of frontier AI, the cluster-level MTBF drops sharply as the number of components grows.
To visualize how quickly scaling can erode confidence, we can look at simple bounds like Markov’s inequality.

If we define X as the number of failed cubes, Markov’s inequality reminds us that as the expected number of failures E[X] increases with cluster size, the probability of staying below a strict failure threshold becomes increasingly difficult to guarantee without systemic architectural changes.
While Markov’s inequality provides a helpful rule of thumb for the risks at scale, we model the availability of scale using a binomial distribution of aggregate cluster health. For a superpod composed of n independent units (cubes), we define the probability of having at least k fully operational and interconnected cubes as the cumulative distribution of the success of n independent trials. To ensure a 95% confidence interval for training productivity, we solve for k where:

Where n represents the total cubes in a superpod and p represents the aggregate cube-level availability.
This model replaces the instance-level model with a topology-aware framework that mirrors actual performance requirements of large-scale training, ensuring that the larger block of compute is healthy and connected and can drive continuous training progress.
Scale of modern AI hardware
To demonstrate this new reliability model, we used Ironwood, Google’s generally available, seventh-generation TPU, and the custom silicon behind advanced models like Gemini and Nano Banana.
Pictured: Part of an Ironwood superpod, directly connecting 9,216 Ironwood TPUs in a single domain.
An Ironwood superpod is a dense, high-performance fabric consisting of 9,216 chips integrated into a single compute domain. It’s organized into 144 cubes, where each cube contains 64 chips. Within these cubes, ICI links create an extremely dense, all-to-all network fabric that provides massive bandwidth and low-latency connectivity for distributed operations within the cube. To form a superpod, 144 cubes are connected using OCS. For large jobs, capacity can be provisioned by interconnecting multiple cubes within a pod into one super-slice, or connecting multiple slices to form a multi-slice cluster. Cubes across multiple superpods can be connected over the datacenter network to run even larger workloads.
Using this model, we determine that the topological availability for an Ironwood superpod is 130 out of 144 cubes available for 95% of the month. This translates to a large compute block of 8,320 chips that are fully operational and interconnected via ICI and OCS, establishing a reliability model specifically optimized for hero jobs (the massive training runs of frontier AI).
The relationship between cluster size and its statistical availability is non-linear. By adjusting the required confidence level, we can identify the slice size that can be supported with statistical certainty. For researchers, this mapping provides a capacity availability curve. An organization with a workload that requires 99% availability for a mission-critical run can optimize their slice size to 125 cubes, while those pushing utmost scale can utilize 130 cubes at the 95% confidence interval.
Capacity availability curve for an Ironwood superpod (144 cubes)
This new reliability model maximizes the utility of the entire superpod through:
-
Full access: This model does not constrain capacity utilization; it focuses on the availability of fully healthy cubes. While a single chip or ICI failure results in the entire cube being classified as unhealthy, customers continue to have access to the remaining capacity within the cube. This makes most of the Ironwood superpod available for use while also optimizing the compute footprint for high-stakes, large-scale training.
-
Optimized resource usage: While the 130-cube model focuses primarily on large-scale training runs, the full superpod remains available for a heterogeneous mix of workloads. This allows researchers to utilize the remaining cubes for research experiments, inference, and dev/test workloads, maximizing the utility of the superpod without compromising the reliability of the main training run.
Our customers are using Ironwood at scale today and this model has empowered them to train their most demanding hero jobs.
Enhancing ML productivity
The goodput metric is the primary measure of ML productivity. Our new reliability standard provides the deterministic foundation for goodput and is engineered to maximize this metric for demanding hero jobs, so that the massive scale infrastructure required for frontier research is ready to perform as a single entity.
This model achieves high scheduling goodput, one of the three goodput metrics, by making the full set of resources available for massive-scale training runs. Combined with the software stack, this infrastructure-level availability helps deliver the high overall goodput. We achieve this through a three-layer reliability model:
-
Infrastructure: TPU superpods provide the capacity footprint to ensure the necessary scale is physically available and connected.
-
Frameworks: JAX and Pathways provide resilience, reconfiguring or hot-swapping around failed nodes to maintain forward progress without requiring a full restart.
-
Application: Fault-tolerance mechanisms like auto-checkpointing and multi-tier checkpointing preserve training state, so that lost progress is minimized in case of a failure.
Enabling the next generation of AI breakthroughs
The cluster-level reliability model marks the beginning of a new standard for the AI era, where an AI supercomputer is a dependable, industrial-scale engine for innovation. By aligning our reliability posture with the demands of frontier models, we’re enabling the next generation of AI breakthroughs to be faster, more reliable, and more predictable. Click here to learn more and get started with TPUs.

