
7 alternatives to selling on Amazon
We explore seven great Amazon alternatives for your business to check out.
7 alternatives to selling on Amazon Read More »
We explore seven great Amazon alternatives for your business to check out.
7 alternatives to selling on Amazon Read More »

Online marketplaces offer the opportunity to showcase your brand and merchandise on large platforms.
A complete guide to online marketplaces Read More »

Need to make some extra cash? Use one of these top online selling sites to offload your goods.
14 best online selling sites and marketplaces Read More »

A complete guide to selling on eBay, including important steps and costs.
How to sell on eBay in 7 steps Read More »

Get started selling on Amazon with this complete guide to the platform.
How to sell on Amazon in 6 steps Read More »
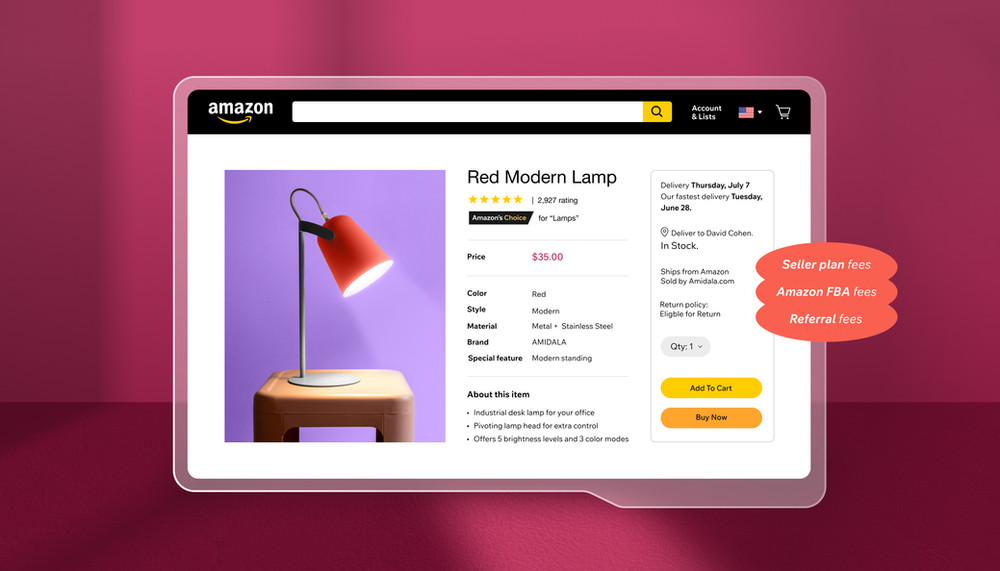
View a breakdown of Amazon seller fees and understand how much it costs to sell on the platform.
Amazon seller fees you need to know about and tips for managing them Read More »

Learn how to sell vintage clothing online with this complete guide.
How to sell vintage clothing online: a complete guide Read More »
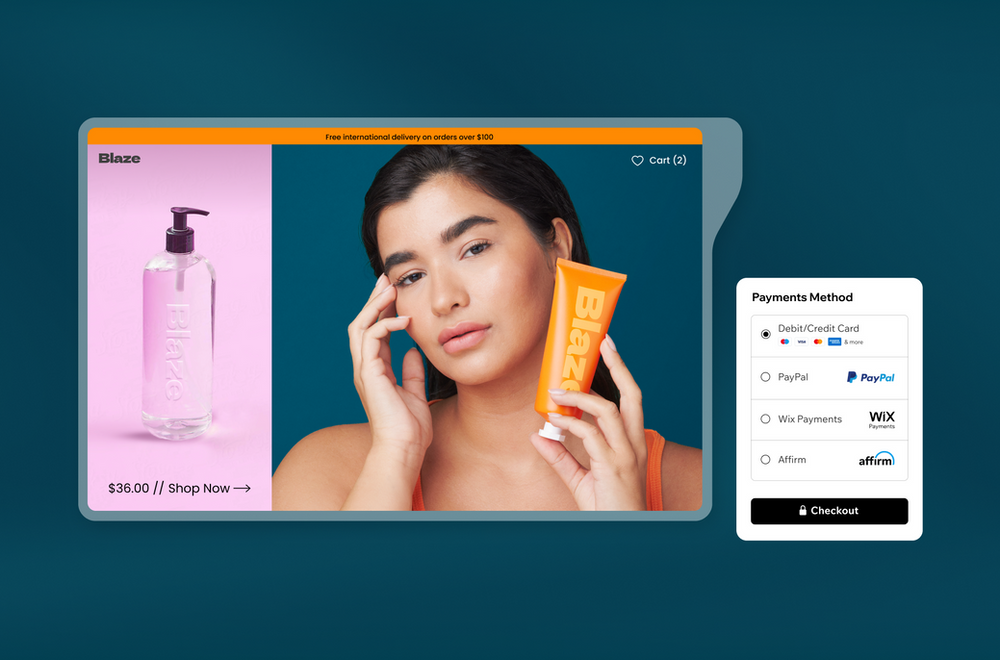
Discover how to accept payments online with our complete guide for businesses.
How to accept payments online: a complete guide for businesses Read More »
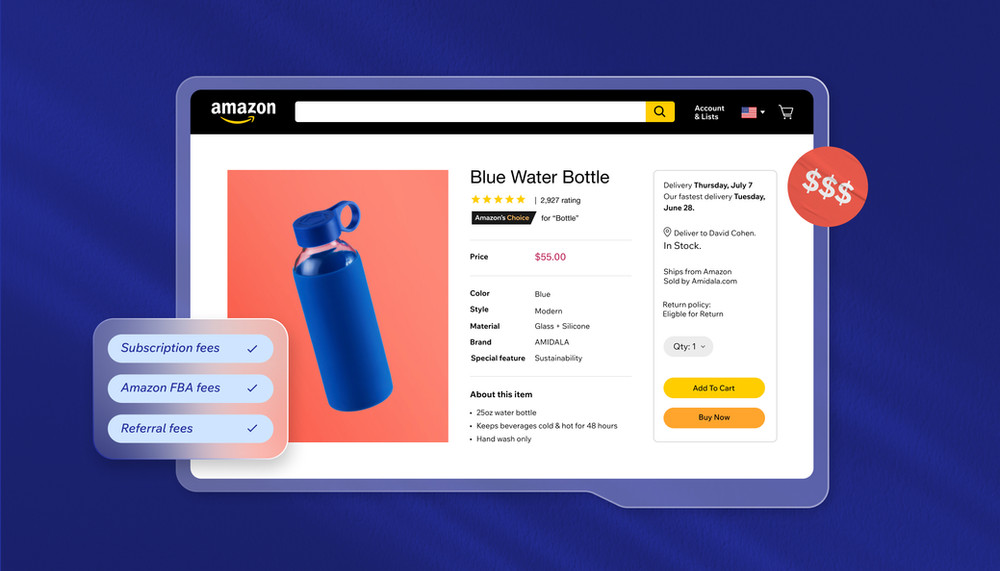
Read more about the costs to sell on Amazon and if its worth it for you.
How much does it cost to sell on Amazon: a detailed breakdown Read More »

null Continue reading I Built a Task Management API in Laravel to Learn the Fundamentals (Here’s What Happened) on SitePoint.