Scaling oncology patient support: How New York Cancer and Blood Specialists transformed customer experience with AWS and Pronetx, now part of Caylent
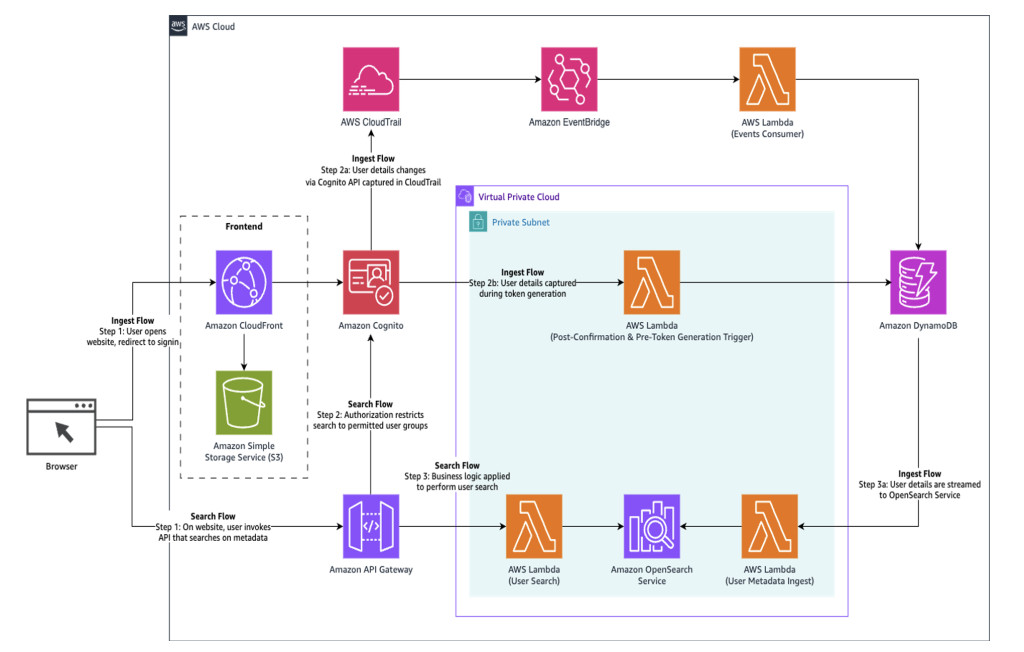
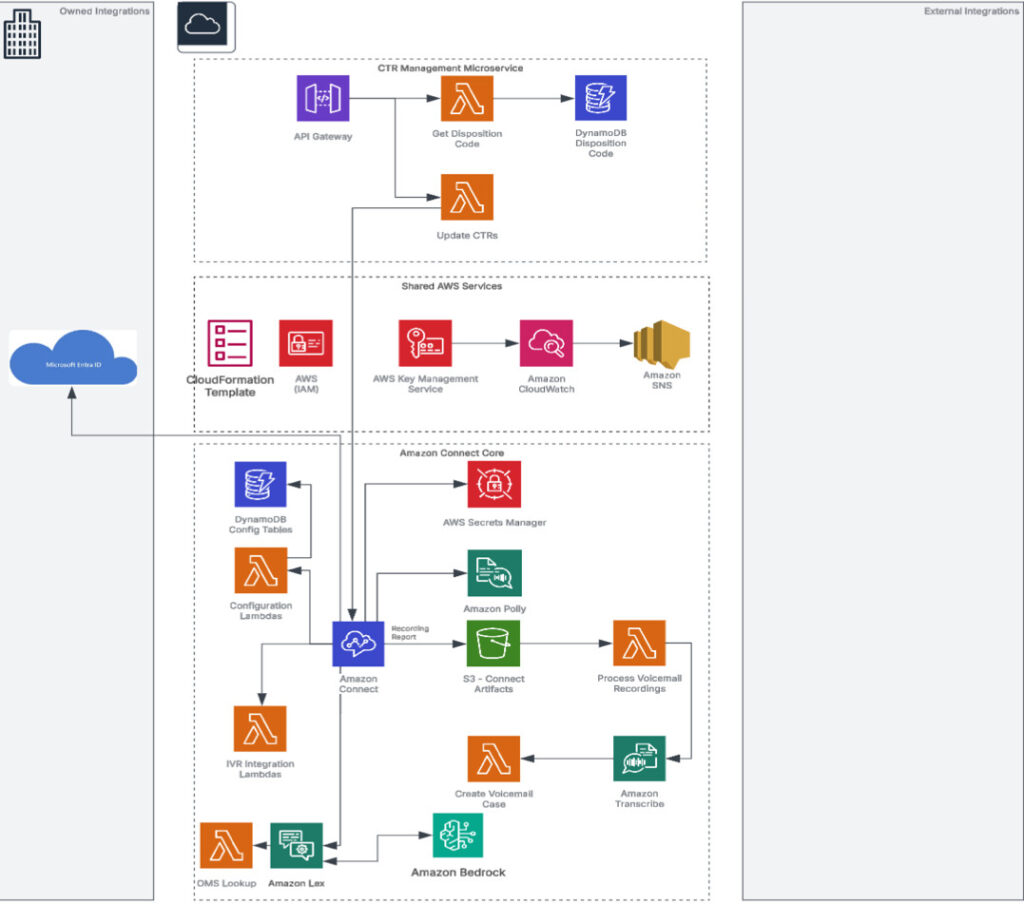
As one of the United States’ leading oncology and hematology providers, the goal of New York Cancer and Blood Specialists (NYCBS) is to provide comprehensive and compassionate care to patients. The organization handles more than 250,000 patient calls every year across over 100 specialized queues and wanted to optimize its manual call handling process. This […]