
Inside the Mind of an AI Girlfriend (or Boyfriend)
Dippy, a startup that offers “uncensored” AI companions, lets you peer into their thought process—sometimes revealing hidden motives.
Inside the Mind of an AI Girlfriend (or Boyfriend) Read More »
Dippy, a startup that offers “uncensored” AI companions, lets you peer into their thought process—sometimes revealing hidden motives.
Inside the Mind of an AI Girlfriend (or Boyfriend) Read More »

Human rights groups have launched a new legal challenge against the use of algorithms to detect error and fraud in France’s welfare system, amid claims that single mothers are disproportionately affected.
Algorithms Policed Welfare Systems For Years. Now They’re Under Fire for Bias Read More »

Most doctors go into medicine because they want to help patients. But today’s health care system requires that doctors spend hours each day on other work — searching through electronic health records (EHRs), writing documentation, coding and billing, prior authorization, and utilization management — often surpassing the time they spend caring for patients. The situation leads to
Equipping doctors with AI co-pilots Read More »
The new frontier in large language models is the ability to “reason” their way through problems. New research from Apple says it’s not quite what it’s cracked up to be.
Apple Engineers Show How Flimsy AI ‘Reasoning’ Can Be Read More »
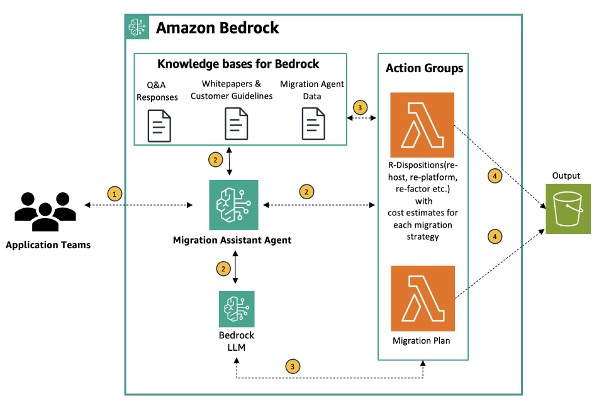
Conducting assessments on application portfolios that need to be migrated to the cloud can be a lengthy endeavor. Despite the existence of AWS Application Discovery Service or the presence of some form of configuration management database (CMDB), customers still face many challenges. These include time taken for follow-up discussions with application teams to review outputs
Accelerate migration portfolio assessment using Amazon Bedrock Read More »

Character.AI lets users create bots in the likeness of any person—without requiring their consent.
Anyone Can Turn You Into an AI Chatbot. There’s Little You Can Do to Stop Them Read More »
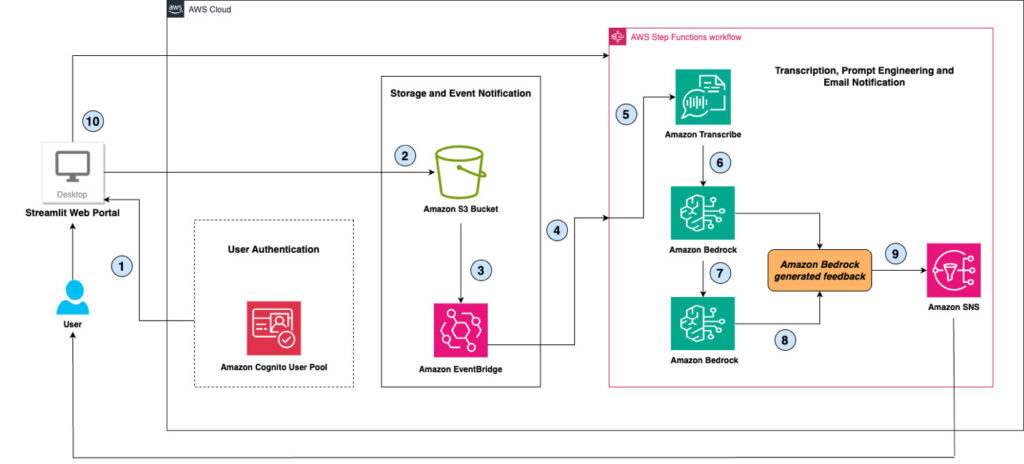
Public speaking is a critical skill in today’s world, whether it’s for professional presentations, academic settings, or personal growth. By practicing it regularly, individuals can build confidence, manage anxiety in a healthy way, and develop effective communication skills leading to successful public speaking engagements. Now, with the advent of large language models (LLMs), you can
This post is co-written with Bar Fingerman from Bria. We are thrilled to announce that Bria 2.3, 2.2 HD, and 2.3 Fast text-to-image foundation models (FMs) from Bria AI are now available in Amazon SageMaker JumpStart. Bria models are trained exclusively on commercial-grade licensed data, providing high standards of safety and compliance with full legal
Bria 2.3, Bria 2.2 HD, and Bria 2.3 Fast are now available in Amazon SageMaker JumpStart Read More »

We’re excited to announce the release of SageMaker Core, a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. This new SDK streamlines data processing, training, and inference and features resource chaining, intelligent defaults, and enhanced logging capabilities. With SageMaker Core, managing ML workloads on
Introducing SageMaker Core: A new object-oriented Python SDK for Amazon SageMaker Read More »

A new smart collar aims to give pet owners the ability to talk to their fur babies. Or at least fake it.
This Talking Pet Collar Is Like a Chatbot for Your Dog Read More »