
OpenAI’s Big Bet That Jony Ive Can Make AI Hardware Work
Io, a firm Ive and Sam Altman cocreated, will now merge with OpenAI.
OpenAI’s Big Bet That Jony Ive Can Make AI Hardware Work Read More »
Io, a firm Ive and Sam Altman cocreated, will now merge with OpenAI.
OpenAI’s Big Bet That Jony Ive Can Make AI Hardware Work Read More »

Mark Brown, who posts game explainers to his Game Maker’s Toolkit channel, says his persona has been plagiarized.
Data privacy is a critical issue for software companies that provide services in the data management space. If they want customers to trust them with their data, software companies need to show and prove that their customers’ data will remain confidential and within controlled environments. Some companies go to great lengths to maintain confidentiality, sometimes

Jack Dorsey’s company went all-in on agents by deploying one capable of building software—and occasionally deleting stuff.
Jack Dorsey’s Block Made an AI Agent to Boost Its Own Productivity Read More »

In her new book Empire of AI, journalist Karen Hao chronicles the anxieties around the OpenAI office in its early days.
The Time Sam Altman Asked for a Countersurveillance Audit of OpenAI Read More »
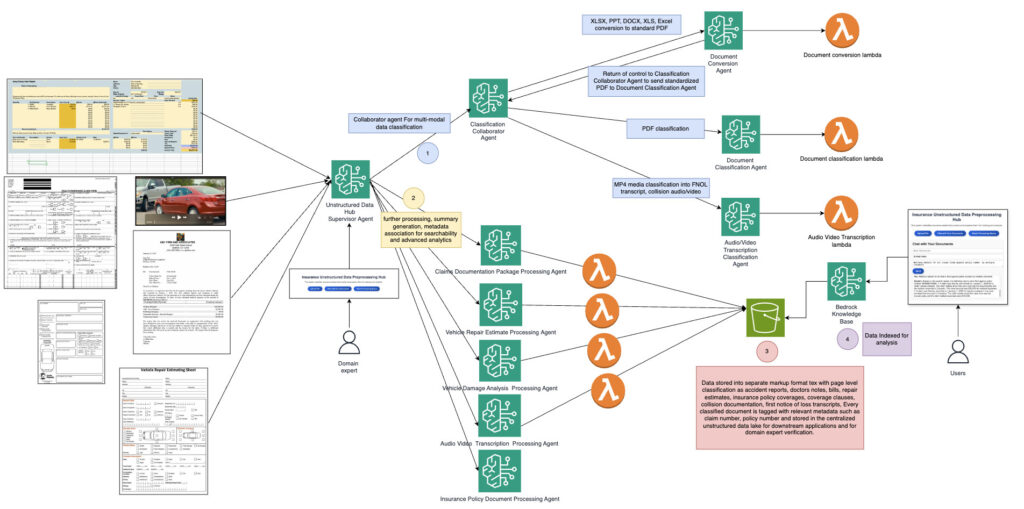
Enterprises—especially in the insurance industry—face increasing challenges in processing vast amounts of unstructured data from diverse formats, including PDFs, spreadsheets, images, videos, and audio files. These might include claims document packages, crash event videos, chat transcripts, or policy documents. All contain critical information across the claims processing lifecycle. Traditional data preprocessing methods, though functional, might
Build a domain‐aware data preprocessing pipeline: A multi‐agent collaboration approach Read More »
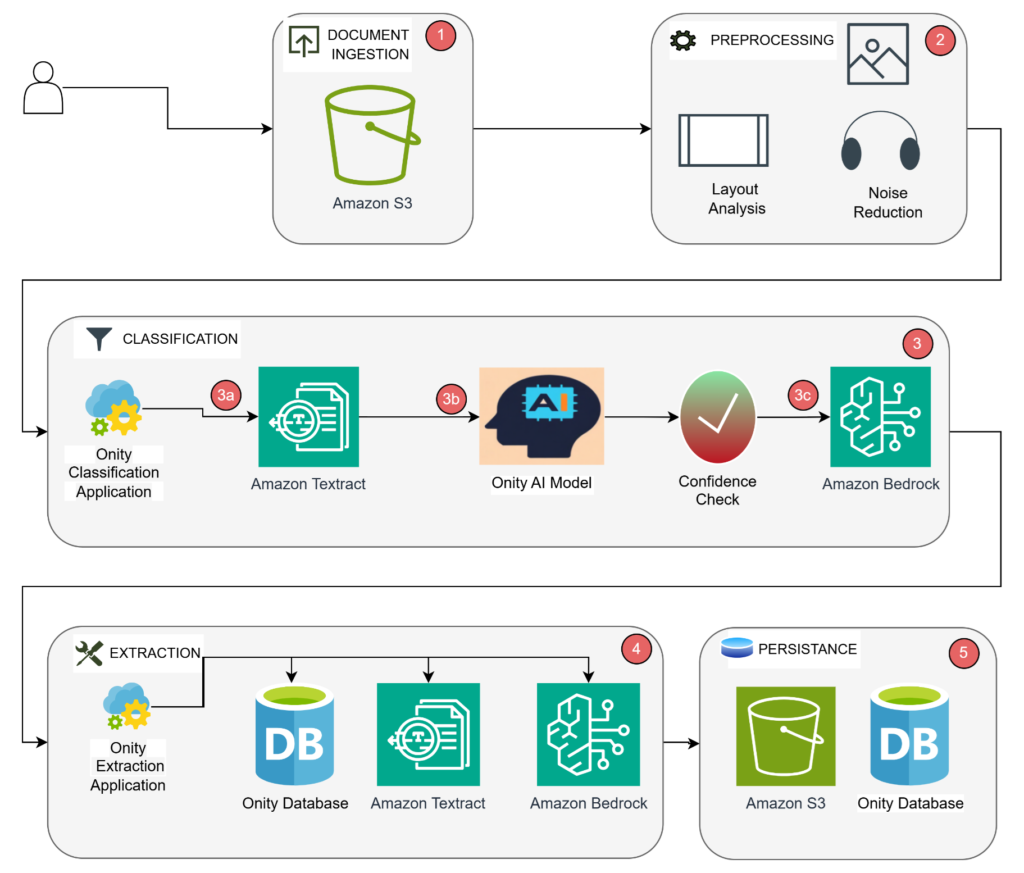
In the mortgage servicing industry, efficient document processing can mean the difference between business growth and missed opportunities. This post explores how Onity Group, a financial services company specializing in mortgage servicing and origination, used Amazon Bedrock and other AWS services to transform their document processing capabilities. Onity Group, founded in 1988, is headquartered in
Google’s new chatbot-style AI Mode search experience, previously an experiment, is launching for US users. Publishers and marketers will have to adjust their search strategies once again.
With AI Mode, Google Search Is About to Get Even Chattier Read More »

Google’s AI models are learning to reason, wield agency, and build virtual models of the real world. The company’s AI lead, Demis Hassabis, says all this—and more—will be needed for true AGI.
Google’s AI Boss Says Gemini’s New Abilities Point the Way to AGI Read More »

The AI doomer and the AI boomer both created each other’s monsters. An excerpt from The Optimist: Sam Altman, OpenAI, and the Race to Invent the Future.
How Peter Thiel’s Relationship With Eliezer Yudkowsky Launched the AI Revolution Read More »