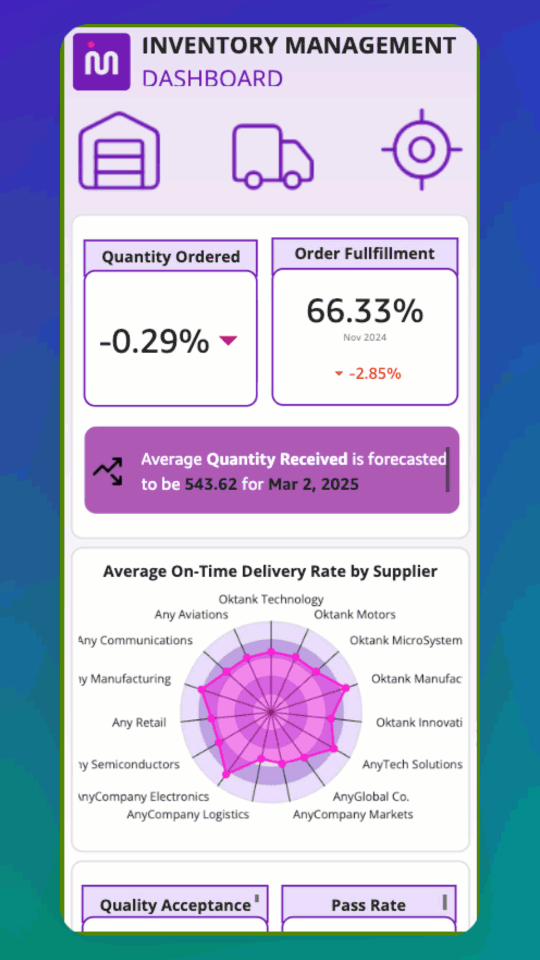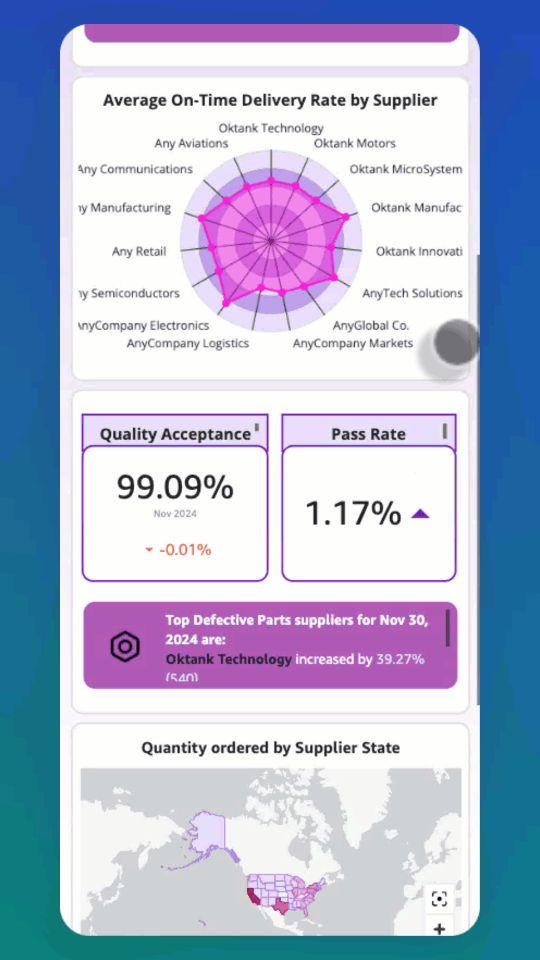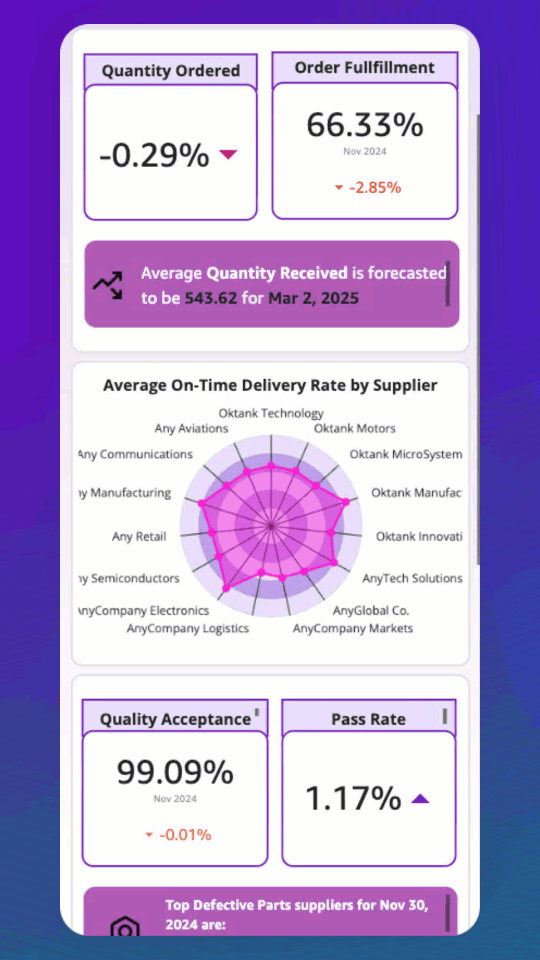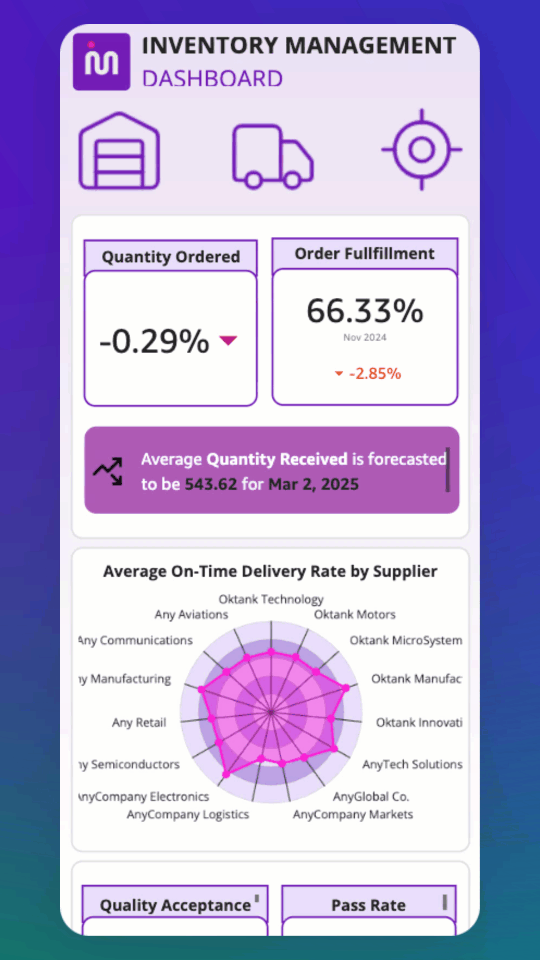
Introducing Mobile Layout for Amazon Quick dashboards
Teams that rely on dashboards for daily decisions often must pinch and zoom to interact with controls originally designed for larger displays. Checking revenue during a morning standup, reviewing pipeline metrics between meetings, or monitoring operations while traveling all require extra effort when the dashboard was built for a desktop screen. Mobile Layout for Amazon […]
Introducing Mobile Layout for Amazon Quick dashboards Read More »