What if you could replace hours of data analysis with a minute-long conversation? Large language models can transform how we bridge the gap between business questions and actionable data insights. For most organizations, this gap remains stubbornly wide, with business teams trapped in endless cycles—decoding metric definitions and hunting for the correct data sources to manually craft each SQL query. Simple business questions can become multi-day ordeals, with analytics teams drowning in routine requests instead of focusing on strategic initiatives.
Amazon’s Worldwide Returns & ReCommerce (WWRR) organization faced this challenge at scale. With users executing over 450,000 SQL queries annually against our petabyte-scale Amazon Redshift data warehouses, our business intelligence and analytics teams had become a critical bottleneck. We needed a self-serve solution that could handle enterprise complexities: thousands of interconnected tables, proprietary business terminology and evolving metrics definitions that vary across business domains, and strict governance requirements.
This post series outlines how WWRR developed the Returns & ReCommerce Data Assist (RRDA), a generative AI-powered conversational interface that transformed data access across all levels of the organization. RRDA empowers over 4000 non-technical users to identify correct metrics, construct validated SQL, and generate complex visualizations—all through natural conversation. The results: 90% faster query resolution (from hours to minutes) with zero dependency on business intelligence teams.
In Part 1, we focus on building a Text-to-SQL solution with Amazon Bedrock, a managed service for building generative AI applications. Specifically, we demonstrate the capabilities of Amazon Bedrock Agents. Part 2 explains how we extended the solution to provide business insights using Amazon Q in QuickSight, a business intelligence assistant that answers questions with auto-generated visualizations.
The fundamentals of Text-to-SQL
Text-to-SQL systems transform natural language questions into database queries through a multi-step process. At its core, these systems must bridge the gap between human communication and structured query language by:
- Understanding user intent and extracting key entities from natural language
- Matching these entities to database schema components (tables, columns, relationships)
- Generating syntactically correct SQL that accurately represents the user’s question
Enterprise implementations face additional challenges, including ambiguous terminology, complex schema relationships, domain-specific business metrics, and real-time query validation. Let’s explore how RRDA implements these principles.
RRDA architecture overview
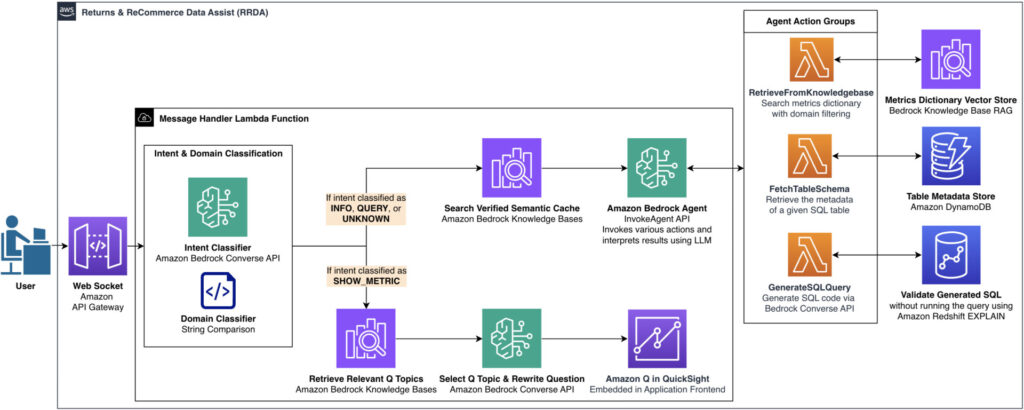
RRDA uses a WebSocket connection through Amazon API Gateway to connect users to AWS Lambda for real-time serverless processing. The following diagram shows the overall architecture of RRDA, highlighting how the user’s messages flow through the system to generate either SQL queries or metric visualizations.

This architecture overview diagram illustrates the system’s dual processing pathways: the upper path handles SQL generation through Amazon Bedrock Agents, while the lower path manages visualization requests via Amazon Q in QuickSight.
In the architecture diagram, the input from the user is classified as an intent and then routed to the most appropriate processing pathway. The architecture features two primary processing pathways:
- For a conversational experience (
INFO,QUERY, andUNKNOWNintents), the system checks our semantic cache for verified responses before routing to an Amazon Bedrock agent that orchestrates between action groups. These action groups are components that define specific operations the agent can help perform:- Retrieve metric definitions with domain filtering
- Fetch SQL table metadata and schemas from Amazon DynamoDB
- Generate SQL code and validate query syntax
- For visualization requests (
SHOW_METRICintent), the system retrieves relevant Amazon QuickSight Q topics, rewrites the question appropriately, then displays visualizations using Amazon Q in QuickSight.
For Part 1 of this post, we focus on the Amazon Bedrock agent that is capable of answering questions about metrics and generating validated SQL. Part 2 will cover the metric visualization pathway using Amazon Q in QuickSight.
Intent and domain classification
RRDA classifies incoming user messages by user intent and relevant business domain. Intent and domain classification occurs simultaneously in parallel threads to minimize latency. The solution categorizes queries into four distinct intents, and routes requests to our agent or Amazon Q in QuickSight accordingly:
- INFO – For informational questions about metrics, definitions, table schemas, and so on (for example, “Explain the resolution index metric”)
- QUERY – For SQL query generation (for example, “Write a query for US resolution index for the past 6 months”)
- SHOW_METRIC – For requests to display visualizations from Amazon Q in QuickSight (for example, “Show me the resolution index in US over the past 6 months”)
- UNKNOWN – For requests that don’t match a known pattern
Intent classification uses a lightweight foundation model (FM) through the Amazon Bedrock Converse API. The system uses a specialized prompt containing numerous examples of each intent type and analyzes both the current user message and recent conversation history to determine the most appropriate category. The system uses structured outputs to constrain the model’s response to one of the four predefined intents.
The following screenshot is an example of a QUERY intent message where a user requests a SQL query for the resolution index metric: “Give me a query for RP resolution index for May 2025 and US marketplace.”

In this example, the system identifies “RP” in the user’s message and correctly maps it to the Returns Processing domain, enabling it to access only the specific tables and metric definitions that uniquely apply to the Returns Processing domain-specific definition of the resolution index metric.
Business domain classification is crucial because enterprises can have metrics that might be calculated differently across different programs, teams, or departments. Our domain classification system uses string comparison to pattern match against a predefined dictionary that maps variations, abbreviations, and aliases to canonical domain names (for example, "rp", "returns-processing", and "return-process" substrings in a user message map to the Returns Processing domain; and "promos" to the Promotions domain). The system tokenizes user messages and identifies whole-word or phrase matches rather than partial string matching to help avoid false positives. This domain context persists across conversation turns, enabling targeted knowledge retrieval and domain-specific processing that improves the response accuracy of our agent.
Amazon Bedrock agent overview
At the core of RRDA’s architecture is an Amazon Bedrock agent powered by Anthropic’s Claude 3.5 Haiku on Amazon Bedrock. This agent serves as the intelligent decision-maker that orchestrates between the following action groups and interprets results:
- RetrieveFromKnowledgeBase – Searches the WWRR metrics dictionary for domain-specific metric definitions, calculation logic, and data sources using metadata filtering
- FetchTableSchema – Gets table information from DynamoDB, providing the agent with up-to-date table schema, column definitions, dimensions for categorical columns, and example queries for that table
- GenerateSQLQuery – Delegates complex SQL generation tasks to Anthropic’s Claude 3.7 Sonnet, passing along retrieved knowledge base information, table schemas, and user requirements
The following sequence diagram shows how the agent orchestrates between different action groups using intent.

Sequence diagram illustrating RRDA’s hybrid model architecture where Anthropic’s Claude 3.5 Haiku orchestrates agent actions for fast retrieval and interaction, while delegating complex SQL generation tasks to Anthropic’s Claude 3.7 Sonnet.
The diagram illustrates how we use a hybrid model architecture that optimizes for both performance and adaptability: Anthropic’s Claude 3.5 Haiku orchestrates the agent for fast information retrieval and interactive responses, while delegating complex SQL generation to Anthropic’s Claude 3.7 Sonnet, which excels at code generation tasks. This balanced approach delivers both responsive interactions and high-quality output.
Metrics dictionary with business domain filtering
RRDA’s metrics dictionary serves as the source of truth for over 1,000 metrics across WWRR’s business domains. Each metric is encoded as a JSON object with metadata (business domain, category, name, definition) and metric usage details (SQL expression, source datasets, filters, granularity). This structure maps business terminology directly to technical implementation for accurate SQL translation.
Each metric object is ingested as an individual chunk into our metrics knowledge base with domain metadata tags. When a user asks “Explain the RP resolution index metric,” RRDA detects Returns Processing as the domain and invokes the RetrieveFromKnowledgeBase action group. This action group retrieves only metrics within that specific business domain by applying a domain filter to the vector search configuration.
For domain-ambiguous queries, the action group identifies potentially relevant domains, and instructs the agent to ask the user to confirm the correct one. The following screenshot is an example of a user interaction where the domain could not be classified.

RRDA demonstrating domain classification and knowledge base retrieval. The system identifies multiple domains with “resolution index” metrics, asks for clarification, then provides detailed metric definitions for the selected Returns Processing domain.
The system’s response short-listed potentially relevant domains that contain the “resolution index” metric. After a domain is detected, subsequent searches are refined with the confirmed domain filter. This targeted retrieval makes sure RRDA accesses only domain-appropriate metric definitions, improving response accuracy while reducing latency by limiting the search space.
Table schema retrieval
The agent invokes the FetchTableSchema action group to get SQL table metadata with low latency. When the agent needs to understand a table’s structure, this action retrieves column definitions, example queries, and usage instructions from the DynamoDB table metadata store. The following screenshot shows an interaction where the user asks for details about a table.

RRDA providing detailed categorical dimension values for the RP aggregate dataset. The agent retrieves and categorizes status buckets from the table metadata, helping users understand available filter options and providing practical usage recommendations.
The agent responded with specific categorical dimension values (for example, “In Warehouse, Quality Check Complete”) that the user can filter by. These distinct values are important context for the agent to generate valid SQL that aligns with business terminology and database structure. However, these distinct values are not available directly through the table schema—but are collected using the workflow in the following diagram.
We created an AWS Step Functions workflow that enriches the DynamoDB table metadata store with rich metadata including table schemas, dimensions, and example queries.

AWS Step Functions workflow for automated table metadata enrichment, updating the DynamoDB metadata store with schema information, categorical dimensions, and usage examples.
The workflow orchestrates the metadata refresh process, running daily to keep information current. The workflow synchronizes schemas from the AWS Glue Data Catalog, uses Amazon Bedrock FMs to identify categorical dimensions worth extracting, populates top K distinct values by running targeted Redshift queries (for example, SELECT DISTINCT column_name FROM table_name ORDER BY COUNT(*) DESC LIMIT K;), and incorporates example usage patterns from Redshift query logs. This automated pipeline reduces manual metadata maintenance while making sure that the table metadata store reflects current data structures, business terminology, and usage patterns.
SQL generation and validation
The heart of our solution is how RRDA actually creates and validates SQL queries. Rather than generating SQL in one step, we designed a smarter approach using the Amazon Bedrock Agents return of control capability, which works like a conversation between different parts of our system. When a user asks a question like “Write a query to find the resolution index for electronics in the US last quarter,” the process unfolds in several steps:
- Our agent consults its knowledge base to identify the correct metric and where this data lives. If anything is unclear, it asks the user follow-up questions like “Are you interested in resolution index for electronics in the US marketplace or North America region?” to verify it understands exactly what’s needed.
- When the agent knows which data source to use, it fetches the detailed schema of that table—column names, data types, dimensions, and example queries—so it knows how the data is organized.
- The
GenerateSQLQueryaction group invokes Anthropic’s Claude 3.7 Sonnet with a specialized prompt for SQL generation using the Amazon Bedrock Converse API. The response returns SQL code with an explanation. - Our system intercepts the action group response using return of control. It extracts the generated SQL and validates it against our Redshift database using an EXPLAIN command, which checks for syntax errors without actually running the query. If the system finds syntax problems, it automatically sends the query back to the Amazon Bedrock FM with specific error information, allowing it to fix itself before proceeding.
- After a valid query is confirmed, the agent receives it and presents it to the user with a clear explanation in simple language. The agent explains what the query does, what filters are applied, and how the results should be interpreted—and is able to answer follow-up questions as needed.
This approach delivers immediate business value: users receive syntactically correct queries that execute on the first attempt, without needing SQL expertise or database schema knowledge. By validating queries using Redshift’s EXPLAIN command—rather than executing them—RRDA maintains security boundaries while ensuring reliability. Users execute validated queries through their existing tools with proper authentication, preserving enterprise access controls while eliminating the trial-and-error cycle of manual SQL development.
Designing a user experience to earn trust
To build trust with users across our organization, we prioritized creating an interface where users can quickly verify RRDA’s reasoning process. When users receive a response, they can choose View agent actions to see exactly which knowledge bases were searched and which table schemas were accessed.

For SQL generation—where accuracy is paramount—we display validation status badges that clearly indicate when queries have passed Redshift syntax verification, building confidence in the output’s reliability.

We also maintain a question bank of curated and verified answers that we serve to users through our semantic cache if a similar question is asked.
![]()
Real-time status indicators keep users informed of each step the agent takes during complex operations, alleviating uncertainty about what’s happening behind the scenes.
![]()
Best practices
Based on our experience building RRDA, the following are best practices for implementing agentic Text-to-SQL solutions:
- Implement domain-aware context – Use business domain classification to retrieve domain-specific metric definitions, making sure that SQL generation respects how metrics are calculated differently across business units.
- Adopt a hybrid model architecture – Use smaller, faster models for orchestration and user interaction, while reserving more powerful models for complex SQL generation tasks to balance performance and accuracy.
- Validate without execution – Implement real-time SQL validation using lightweight commands like Redshift EXPLAIN to catch syntax issues without executing the query. Separating query generation from execution reduces errors while preserving existing authentication boundaries.
- Automate metadata maintenance – Build pipelines that continuously refresh metadata, such as schema information and dimensions, without manual intervention to make sure the system references up-to-date information.
- Design for transparency and user engagement – Build trust by exposing agent reasoning, intermediate steps, and providing clear explanations of generated SQL. Implement real-time status indicators and progress updates for multi-step processes with response times of 15–60 seconds. Transparent processing feedback maintains user engagement and builds confidence during complex operations like SQL generation and knowledge retrieval.
Conclusion
The Returns & ReCommerce Data Assist transforms data access at WWRR by converting natural language into validated SQL queries through Amazon Bedrock. With our domain-aware approach with real-time validation, business users can retrieve accurate data without SQL expertise, dramatically shortening the path from questions to insights. This Text-to-SQL capability is just the first step—Part 2 will explore extending the solution with automated visualization using Amazon Q in QuickSight.
About the authors
 Dheer Toprani is a System Development Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazon’s operations. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
Dheer Toprani is a System Development Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazon’s operations. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
 Nicolas Alvarez is a Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team, focusing on building and optimizing recommerce data systems. He plays a key role in developing advanced technical solutions, including Apache Airflow implementations and front-end architecture for the team’s web presence. His work is crucial in enabling data-driven decision making for Amazon’s reverse logistics operations and improving the efficiency of end-of-lifecycle product management.
Nicolas Alvarez is a Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team, focusing on building and optimizing recommerce data systems. He plays a key role in developing advanced technical solutions, including Apache Airflow implementations and front-end architecture for the team’s web presence. His work is crucial in enabling data-driven decision making for Amazon’s reverse logistics operations and improving the efficiency of end-of-lifecycle product management.
 Lakshdeep Vatsa is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data and reporting solutions. At Amazon, he plays a key role in developing scalable data pipelines, improving data quality, and enabling actionable insights for Reverse Logistics and ReCommerce operations. He is deeply passionate about enhancing self-service experiences for users and consistently seeks opportunities to utilize generative BI capabilities to solve complex customer challenges.
Lakshdeep Vatsa is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data and reporting solutions. At Amazon, he plays a key role in developing scalable data pipelines, improving data quality, and enabling actionable insights for Reverse Logistics and ReCommerce operations. He is deeply passionate about enhancing self-service experiences for users and consistently seeks opportunities to utilize generative BI capabilities to solve complex customer challenges.
 Karam Muppidi is a Senior Engineering Manager at Amazon Retail, leading data engineering, infrastructure, and analytics teams within the Worldwide Returns and ReCommerce organization. He specializes in using LLMs and multi-agent architectures to transform data analytics and drive organizational adoption of AI tools. He has extensive experience developing enterprise-scale data architectures, analytics services, and governance strategies using AWS and third-party tools. Prior to his current role, Karam developed petabyte-scale data and compliance solutions for Amazon’s Fintech and Merchant Technologies divisions.
Karam Muppidi is a Senior Engineering Manager at Amazon Retail, leading data engineering, infrastructure, and analytics teams within the Worldwide Returns and ReCommerce organization. He specializes in using LLMs and multi-agent architectures to transform data analytics and drive organizational adoption of AI tools. He has extensive experience developing enterprise-scale data architectures, analytics services, and governance strategies using AWS and third-party tools. Prior to his current role, Karam developed petabyte-scale data and compliance solutions for Amazon’s Fintech and Merchant Technologies divisions.
 Sreeja Das is a Principal Engineer in the Returns and ReCommerce organization at Amazon. In her 10+ years at the company, she has worked at the intersection of high-scale distributed systems in eCommerce and Payments, Enterprise services, and Generative AI innovations. In her current role, Sreeja is focusing on system and data architecture transformation to enable better traceability and self-service in Returns and ReCommerce processes. Previously, she led architecture and tech strategy of some of Amazon’s core systems including order and refund processing systems and billing systems that serve tens of trillions of customer requests everyday.
Sreeja Das is a Principal Engineer in the Returns and ReCommerce organization at Amazon. In her 10+ years at the company, she has worked at the intersection of high-scale distributed systems in eCommerce and Payments, Enterprise services, and Generative AI innovations. In her current role, Sreeja is focusing on system and data architecture transformation to enable better traceability and self-service in Returns and ReCommerce processes. Previously, she led architecture and tech strategy of some of Amazon’s core systems including order and refund processing systems and billing systems that serve tens of trillions of customer requests everyday.