This post is co-written by Kevin Plexico and Shakun Vohra from Deltek.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. Retrieval Augmented Generation (RAG) has emerged as a leading method for using the power of large language models (LLMs) to interact with documents in natural language.
This post provides an overview of a custom solution developed by the AWS Generative AI Innovation Center (GenAIIC) for Deltek, a globally recognized standard for project-based businesses in both government contracting and professional services. Deltek serves over 30,000 clients with industry-specific software and information solutions.
In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents. The solution uses AWS services including Amazon Textract, Amazon OpenSearch Service, and Amazon Bedrock. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) and LLMs from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their data ingestion pipeline.
What is RAG?
RAG is a process that optimizes the output of LLMs by allowing them to reference authoritative knowledge bases outside of their training data sources before generating a response. This approach addresses some of the challenges associated with LLMs, such as presenting false, outdated, or generic information, or creating inaccurate responses due to terminology confusion. RAG enables LLMs to generate more relevant, accurate, and contextual responses by cross-referencing an organization’s internal knowledge base or specific domains, without the need to retrain the model. It provides organizations with greater control over the generated text output and offers users insights into how the LLM generates the response, making it a cost-effective approach to improve the capabilities of LLMs in various contexts.
The main challenge
Applying RAG for Q&A on a single document is straightforward, but applying the same across multiple related documents poses some unique challenges. For example, when using question answering on documents that evolve over time, it is essential to consider the chronological sequence of the documents if the question is about a concept that has transformed over time. Not considering the order could result in providing an answer that was accurate at a past point but is now outdated based on more recent information across the collection of temporally aligned documents. Properly handling temporal aspects is a key challenge when extending question answering from single documents to sets of interlinked documents that progress over the course of time.
Solution overview
As an example use case, we describe Q&A on two temporally related documents: a long draft request-for-proposal (RFP) document, and a related subsequent government response to a request-for-information (RFI response), providing additional and revised information.
The solution develops a RAG approach in two steps.
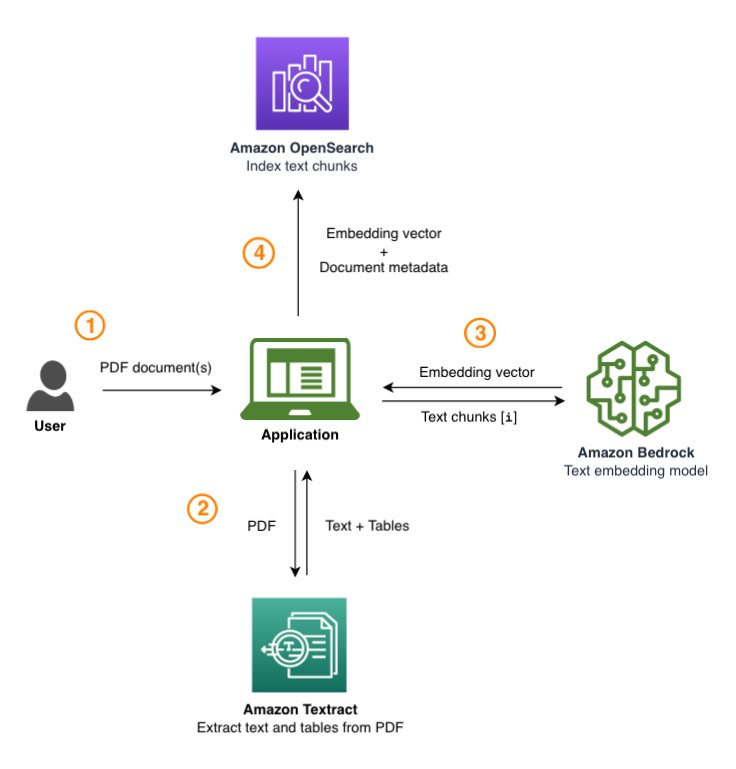
The first step is data ingestion, as shown in the following diagram. This includes a one-time processing of PDF documents. The application component here is a user interface with minor processing such as splitting text and calling the services in the background. The steps are as follows:
The user uploads documents to the application.
The application uses Amazon Textract to get the text and tables from the input documents.
The text embedding model processes the text chunks and generates embedding vectors for each text chunk.
The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service.
The second step is Q&A, as shown in the following diagram. In this step, the user asks a question about the ingested documents and expects a response in natural language. The application component here is a user interface with minor processing such as calling different services in the background. The steps are as follows:
The user asks a question about the documents.
The application retrieves an embedding representation of the input question.
The application passes the retrieved data from OpenSearch Service and the query to Amazon Bedrock to generate a response. The model performs a semantic search to find relevant text chunks from the documents (also called context). The embedding vector maps the question from text to a space of numeric representations.
The question and context are combined and fed as a prompt to the LLM. The language model generates a natural language response to the user’s question.
We used Amazon Textract in our solution, which can convert PDFs, PNGs, JPEGs, and TIFFs into machine-readable text. It also formats complex structures like tables for easier analysis. In the following sections, we provide an example to demonstrate Amazon Textract’s capabilities.
OpenSearch is an open source and distributed search and analytics suite derived from Elasticsearch. It uses a vector database structure to efficiently store and query large volumes of data. OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing hundreds of trillions of requests per month. We used OpenSearch Service and its underlying vector database to do the following:
Index documents into the vector space, allowing related items to be located in proximity for improved relevancy
Quickly retrieve related document chunks at the question answering step using approximate nearest neighbor search across vectors
The vector database inside OpenSearch Service enabled efficient storage and fast retrieval of related data chunks to power our question answering system. By modeling documents as vectors, we could find relevant passages even without explicit keyword matches.
Text embedding models are machine learning (ML) models that map words or phrases from text to dense vector representations. Text embeddings are commonly used in information retrieval systems like RAG for the following purposes:
Document embedding – Embedding models are used to encode the document content and map them to an embedding space. It is common to first split a document into smaller chunks such as paragraphs, sections, or fixed size chunks.
Query embedding – User queries are embedded into vectors so they can be matched against document chunks by performing semantic search.
For this post, we used the Amazon Titan model, Amazon Titan Embeddings G1 – Text v1.2, which intakes up to 8,000 tokens and outputs a numerical vector of 1,536 dimensions. The model is available through Amazon Bedrock.
Amazon Bedrock provides ready-to-use FMs from top AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon. It offers a single interface to access these models and build generative AI applications while maintaining privacy and security. We used Anthropic Claude v2 on Amazon Bedrock to generate natural language answers given a question and a context.
In the following sections, we look at the two stages of the solution in more detail.
Data ingestion
First, the draft RFP and RFI response documents are processed to be used at the Q&A time. Data ingestion includes the following steps:
Documents are passed to Amazon Textract to be converted into text.
To better enable our language model to answer questions about tables, we created a parser that converts tables from the Amazon Textract output into CSV format. Transforming tables into CSV improves the model’s comprehension. For instance, the following figures show part of an RFI response document in PDF format, followed by its corresponding extracted text. In the extracted text, the table has been converted to CSV format and sits among the rest of the text.
For long documents, the extracted text may exceed the LLM’s input size limitation. In these cases, we can divide the text into smaller, overlapping chunks. The chunk sizes and overlap proportions may vary depending on the use case. We apply section-aware chunking, (perform chunking independently on each document section), which we discuss in our example use case later in this post.
Some classes of documents may follow a standard layout or format. This structure can be used to optimize data ingestion. For example, RFP documents tend to have a certain layout with defined sections. Using the layout, each document section can be processed independently. Also, if a table of contents exists but is not relevant, it can potentially be removed. We provide a demonstration of detecting and using document structure later in this post.
The embedding vector for each text chunk is retrieved from an embedding model.
At the last step, the embedding vectors are indexed into an OpenSearch Service database. In addition to the embedding vector, the text chunk and document metadata such as document, document section name, or document release date are also added to the index as text fields. The document release date is useful metadata when documents are related chronologically, so that LLM can identify the most updated information. The following code snippet shows the index body:
Q&A
In the Q&A phrase, users can submit a natural language question about the draft RFP and RFI response documents ingested in the previous step. First, semantic search is used to retrieve relevant text chunks to the user’s question. Then, the question is augmented with the retrieved context to create a prompt. Finally, the prompt is sent to Amazon Bedrock for an LLM to generate a natural language response. The detailed steps are as follows:
An embedding representation of the input question is retrieved from the Amazon Titan embedding model on Amazon Bedrock.
The question’s embedding vector is used to perform semantic search on OpenSearch Service and find the top K relevant text chunks. The following is an example of a search body passed to OpenSearch Service. For more details see the OpenSearch documentation on structuring a search query.
Any retrieved metadata, such as section name or document release date, is used to enrich the text chunks and provide more information to the LLM, such as the following:
The input question is combined with retrieved context to create a prompt. In some cases, depending on the complexity or specificity of the question, an additional chain-of-thought (CoT) prompt may need to be added to the initial prompt in order to provide further clarification and guidance to the LLM. The CoT prompt is designed to walk the LLM through the logical steps of reasoning and thinking that are required to properly understand the question and formulate a response. It lays out a type of internal monologue or cognitive path for the LLM to follow in order to comprehend the key information within the question, determine what kind of response is needed, and construct that response in an appropriate and accurate way. We use the following CoT prompt for this use case:
The prompt is passed to an LLM on Amazon Bedrock to generate a response in natural language. We use the following inference configuration for the Anthropic Claude V2 model on Amazon Bedrock. The Temperature parameter is usually set to zero for reproducibility and also to prevent LLM hallucination. For regular RAG applications, top_k and top_p are usually set to 250 and 1, respectively. Set max_tokens_to_sample to maximum number of tokens expected to be generated (1 token is approximately 3/4 of a word). See Inference parameters for more details.
Example use case
As a demonstration, we describe an example of Q&A on two related documents: a draft RFP document in PDF format with 167 pages, and an RFI response document in PDF format with 6 pages released later, which includes additional information and updates to the draft RFP.
The following is an example question asking if the project size requirements have changed, given the draft RFP and RFI response documents:
Have the original scoring evaluations changed? if yes, what are the new project sizes?
The following figure shows the relevant sections of the draft RFP document that contain the answers.
The following figure shows the relevant sections of the RFI response document that contain the answers.
For the LLM to generate the correct response, the retrieved context from OpenSearch Service should contain the tables shown in the preceding figures, and the LLM should be able to infer the order of the retrieved contents from metadata, such as release dates, and generate a readable response in natural language.
The following are the data ingestion steps:
The draft RFP and RFI response documents are uploaded to Amazon Textract to extract text and tables as the content. Additionally, we used regular expression to identify document sections and table of contents (see the following figures, respectively). The table of contents can be removed for this use case because it doesn’t have any relevant information.
We split each document section independently into smaller chunks with some overlaps. For this use case, we used a chunk size of 500 tokens with the overlap size of 100 tokens (1 token is approximately 3/4 a word). We used a BPE tokenizer, where each token corresponds to about 4 bytes.
An embedding representation of each text chunk is obtained using the Amazon Titan Embeddings G1 – Text v1.2 model on Amazon Bedrock.
Each text chunk is stored into an OpenSearch Service index along with metadata such as section name and document release date.
The Q&A steps are as follows:
The input question is first transformed to a numeric vector using the embedding model. The vector representation used for semantic search and retrieval of relevant context in the next step.
The top K relevant text chunk and metadata are retrieved from OpenSearch Service.
The opensearch_result_to_context function and the prompt template (defined earlier) are used to create the prompt given the input question and retrieved context.
The prompt is sent to the LLM on Amazon Bedrock to generate a response in natural language. The following is the response generated by Anthropic Claude v2, which matched with the information presented in the draft RFP and RFI response documents. The question was “Have the original scoring evaluations changed? If yes, what are the new project sizes?” Using CoT prompting, the model can correctly answer the question.
Key features
The solution contains the following key features:
Section-aware chunking – Identify document sections and split each section independently into smaller chunks with some overlaps to optimize data ingestion.
Table to CSV transformation – Convert tables extracted by Amazon Textract into CSV format to improve the language model’s ability to comprehend and answer questions about tables.
Adding metadata to index – Store metadata such as section name and document release date along with text chunks in the OpenSearch Service index. This allowed the language model to identify the most up-to-date or relevant information.
CoT prompt – Design a chain-of-thought prompt to provide further clarification and guidance to the language model on the logical steps needed to properly understand the question and formulate an accurate response.
These contributions helped improve the accuracy and capabilities of the solution for answering questions about documents. In fact, based on Deltek’s subject matter experts’ evaluations of LLM-generated responses, the solution achieved a 96% overall accuracy rate.
Conclusion
This post outlined an application of generative AI for question answering across multiple government solicitation documents. The solution discussed was a simplified presentation of a pipeline developed by the AWS GenAIIC team in collaboration with Deltek. We described an approach to enable Q&A on lengthy documents published separately over time. Using Amazon Bedrock and OpenSearch Service, this RAG architecture can scale for enterprise-level document volumes. Additionally, a prompt template was shared that uses CoT logic to guide the LLM in producing accurate responses to user questions. Although this solution is simplified, this post aimed to provide a high-level overview of a real-world generative AI solution for streamlining review of complex proposal documents and their iterations.
Deltek is actively refining and optimizing this solution to ensure it meets their unique needs. This includes expanding support for file formats other than PDF, as well as adopting more cost-efficient strategies for their data ingestion pipeline.
Learn more about prompt engineering and generative AI-powered Q&A in the Amazon Bedrock Workshop. For technical support or to contact AWS generative AI specialists, visit the GenAIIC webpage.
Resources
To learn more about Amazon Bedrock, see the following resources:
Amazon Bedrock Workshop
Amazon Bedrock User Guide
To learn more about OpenSearch Service, see the following resources:
Amazon OpenSearch Service Documentation
Amazon OpenSearch Workshop
See the following links for RAG resources on AWS:
Retrieval augmented generation (RAG)
Knowledge Bases for Amazon Bedrock
About the Authors
Kevin Plexico is Senior Vice President of Information Solutions at Deltek, where he oversees research, analysis, and specification creation for clients in the Government Contracting and AEC industries. He leads the delivery of GovWin IQ, providing essential government market intelligence to over 5,000 clients, and manages the industry’s largest team of analysts in this sector. Kevin also heads Deltek’s Specification Solutions products, producing premier construction specification content including MasterSpec® for the AIA and SpecText.
Shakun Vohra is a distinguished technology leader with over 20 years of expertise in Software Engineering, AI/ML, Business Transformation, and Data Optimization. At Deltek, he has driven significant growth, leading diverse, high-performing teams across multiple continents. Shakun excels in aligning technology strategies with corporate goals, collaborating with executives to shape organizational direction. Renowned for his strategic vision and mentorship, he has consistently fostered the development of next-generation leaders and transformative technological solutions.
Amin Tajgardoon is an Applied Scientist at the AWS Generative AI Innovation Center. He has an extensive background in computer science and machine learning. In particular, Amin’s focus has been on deep learning and forecasting, prediction explanation methods, model drift detection, probabilistic generative models, and applications of AI in the healthcare domain.
Anila Joshi has more than a decade of experience building AI solutions. As an Applied Science Manager at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.
Yash Shah and his team of scientists, specialists and engineers at AWS Generative AI Innovation Center, work with some of AWS most strategic customers on helping them realize art of the possible with Generative AI by driving business value. Yash has been with Amazon for more than 7.5 years now and has worked with customers across healthcare, sports, manufacturing and software across multiple geographic regions.
Jordan Cook is an accomplished AWS Sr. Account Manager with nearly two decades of experience in the technology industry, specializing in sales and data center strategy. Jordan leverages his extensive knowledge of Amazon Web Services and deep understanding of cloud computing to provide tailored solutions that enable businesses to optimize their cloud infrastructure, enhance operational efficiency, and drive innovation.