Databases have introduced new AI-powered SQL functions which take natural language instructions as input and are evaluated using LLMs. They leverage the power of LLMs to answer new kinds of queries: Which product reviews are negative about durability? Which customer support tickets have been resolved by providing a workaround?
These new AI functions push the boundaries of what is possible in a SQL query engine by bringing the semantic understanding of LLMs to your data, thus enabling previously impossible analyses and applications. But, their cost and performance limited their applicability. LLM invocations add 10-100x to the overall query latency and ~1000x on cost. This is much too slow for operational databases. In analytics, a medium-sized query on 10-100 millions of rows would consume an amount of tokens that is prohibitively expensive for some applications.
Google Cloud has published a new paper at SIGMOD where we show how to accelerate and reduce the cost of LLM-powered AI functions by using proxy models. Proxy models are cost-optimized ultra-lightweight models tailored to a specific query (aka prompt) and tuned for your data. They replace the majority of LLM calls during query execution (thus the name proxy model) and can be trained on-the-fly or ahead of time. The fundamental ideas behind proxy models were proposed in Universal Query Engine (UQE) at NeurIPS 2024 by Google DeepMind.
Our paper shows that proxy models are automatically applicable in many (but not all) cases, sometimes with no loss of quality, sometimes with minor quality loss and a few times with a gain of quality. BigQuery and AlloyDB already implement this optimization under the optimized mode feature for AI.IF (BigQuery docs, AlloyDB docs) and AI.CLASSIFY (BigQuery docs). This article is a tl;dr of the SIGMOD paper and provides the key intuitions on three questions:
-
Why do proxy models work so accurately for so many cases, even though they are so much more performant than LLMs?
-
How do they work?
-
In which use cases do they deliver accurate answers? In which cases they fail and accuracy needs LLMs.
Why Proxy Models Work Accurately at Ultra Low Latency and Cost?
How can an ultra-lightweight proxy model, such as the logistic regression currently in use at BigQuery and AlloyDB, have the semantic understanding power of LLMs, which is required for accurate question answering? The key intuition is that these proxy models input rich embeddings of the data that they query. By default, we are using the Gemini embedding generators, which do the heavy lifting of bringing semantics to your data when the embeddings are generated.
Then the ultra low latency and cost are easy to see: Since embeddings are generated once and used many times, the cost of bringing semantics to your data is amortized; it now happens once as opposed to happening for each query. Furthermore, the proxy models run fast in the CPU — no need for dedicated hardware.
We hope that we gave you good intuitions for why proxy models work. But a word of caution is also needed: Proxy models are fundamentally an approximation technique more limited than LLMs. Proxy models perform well on some prompts but may be deficient to LLMs in others. Case in point, the SIGMOD26 paper shows that the proxy/LLM predictive performance (as measured by F1) ratio ranged from 90% to 116% in 10 benchmarks. For example, they might break down on problems that require reasoning to connect multiple semantic concepts. Rather, think of them as specializing the model to your query and your data.
The good news is that the query processors automatically check the effectiveness and feasibility of implementing AI Functions by proxies. Let’s see how they do it.
How Proxy Models Work?
Let’s go through a simple example of a semantic filter (AI.IF). Our taste in movies is very particular: We like movies with an interesting plot and great cinematography. The query below processes IMDB reviews to find such movies.
- code_block
- <ListValue: [StructValue([(‘code’, ‘SELECTrn DISTINCT t.primary_titlern FROM rn bigquery-public-data.imdb.reviews r, rn bigquery-public-data.imdb.title_basics trn WHERE TRUErn AND r.movie_id = t.tconstrn AND AI.IF(“Is the plot interesting? Review: ” || r.review, rn embeddings => r.review_embedded)rn AND AI.IF(“Does the review praise the cinematography? Review: ” || r.review, rn embeddings => r.review_embedded)’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x7f3da79ec1f0>)])]>
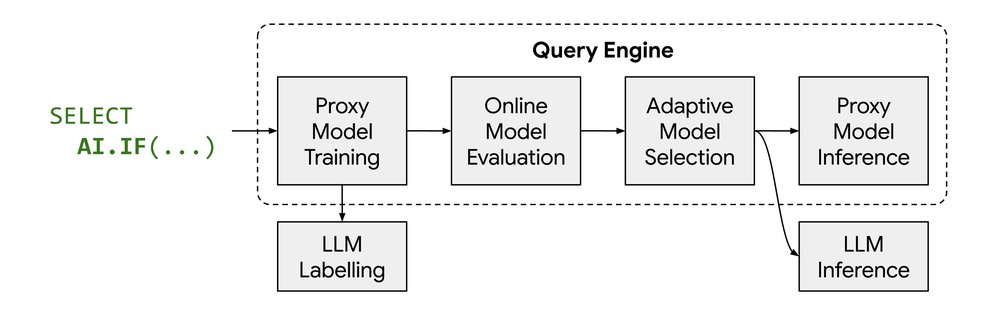
The column review contains the free-form text of the review. The column review_embedded contains Gemini embeddings of the review text. When you run this query in BigQuery, the query engine will
-
For the first AI.IF, create a training samples’ set consisting of about one thousand rows of the input relation, the
imdb.reviewstable. -
Use an LLM to label the first sample set, marking each review as either TRUE (yes, the plot is interesting) or FALSE (no, the plot is not interesting).
-
Train a proxy model for the first AI.IF using the labels computed at the previous step.
-
Create a test sample set of rows for the first AI.IF and evaluate the quality of the proxy model on this test set.
-
Based on the eval results, the optimizer adaptively decides to either perform inference using the proxy model or fall back to LLM inference for the first AI.IF
-
Repeat the above steps for the second AI.IF

In BigQuery, all steps happen on-the-fly during query execution. AlloyDB, being an operational database that targets sub-second latencies, avoids the online proxy model training and the online evaluation. Rather, the query’s proxy models are computed ahead of time in a PREPARE statement, thus moving the cost of sampling, labelling and training out of the critical query path. This enables the offline creation of a big pool of PREPARE statements, while the application chooses the proper PREPARE statement and executes it in the online path.
Let’s take a step back and look at what is really happening at step #3. The proxy model uses each dimension of the review embeddings (from review_embedded) as its features. Modern dense embedding models like Gecko or Gemini capture myriads of semantic notions. In our example with movie reviews, at a high level of abstraction, relevant notions would include: “aesthetic”, “thought-provoking plot”, “underwhelming plot”, or perhaps “boring movie”. We stress the “high level of abstraction” because, in the binary “language” of foundation models, all these notions (and many more) are spread in the numbers of the dense embedding. Do not expect to spot a dimension that corresponds directly to cinematography. Importantly, the embedding space contains many more notions that are irrelevant to our task. The training of the proxy model essentially weighs heavily relevant notions and discards irrelevant ones.
A proxy model (green plane) isolating relevant semantic notions by cutting the embedding space (blue sphere)
Now, let’s enter the details of the particular proxy model, which is used by our current version: logistic regression. To visualize what is happening, think of embeddings as unit vectors forming a (hyper)sphere. For a binary classification task, the proxy model essentially cuts the sphere in two halves. In our example “aesthetic” and “thought-provoking plot” would fall on one side of the plane, whereas “underwhelming plot” and “boring movie” would be on the other side. Conceptually, the orientation of the plane determines which semantic notions are more relevant.
Importantly, the proxy model is tuned for your data and your question: The training of the proxy used a high quality LLM to label a sample from your data for the particular question.
Revisiting when Proxy Models Work
We can now see more clearly what distinguishes cases that proxy models work from cases they don’t: proxy models work well for prompts that can be decided by detecting semantic notions in the embedding space. They will fail for complex prompts that require forms of reasoning that go beyond detecting patterns in the embedding model.
The good news is that, in practice, we have observed that proxy models work for a large class of AI+SQL queries. The SIGMOD26 paper provides a comprehensive evaluation, showing that proxies worked in 11 benchmarks. Specifically, in 10 benchmarks the ratio of proxy F1 to LLM F1 ranged from 90% to 102% and in the 11th benchmark (Amazon Reviews) it was 116%. Notice that the proxy may even deliver better accuracy because it got the benefit of being trained by multiple samples as opposed to the LLM that addressed each row as a new problem.
There is a second limitation currently: extreme selectivities. Notice that Step 1 collects samples. It needs to collect many examples for TRUE and many examples for FALSE. Multiple sophisticated techniques are employed to achieve this, even when the TRUEs are many more than the FALSEs or vice versa. However, no purely sampling technique can confront cases of extreme selectivity, i.e., cases of very few TRUEs or very few FALSEs. This is the reason that the proxies will not be employed in such extreme selectivity cases. However, notice that this problem is fundamentally addressable by various techniques.
Why isn’t Vector Search Enough?
Proxy models appear … suspiciously close to vector search. After all, they also input vector embeddings. Why not just vector search? There are two reasons why vector search is not enough: The obvious one is that proxies are not rankers; they are classifiers: multiclass classifiers (AI.CLASSIFY) or binary classifiers (AI.IF). But, even if you narrow down to just AI.IF, an attempt to simulate AI.IF with vector search will be both hard-to-setup and will give suboptimal results. While proxy models are tailored to your data and your prompts, vector search is based on generic distance functions (such as cosine).
Experimental Results
We present here a subset of characteristic benchmarks from the SIGMOD26 paper. We compare the accuracy of proxy models with using LLM inference on all rows. In terms of quality, the relative accuracy varies from 0.92 (lowest) to 1.16 (highest), which means that for some tasks, proxy models perform slightly better than straight LLM inference.
|
Dataset |
Prompt |
F1 (Proxy) |
F1 (LLM) |
Relative (Proxy/LLM) |
|
Amazon Reviews 10k |
Review is {sentiment label} |
0.860 |
0.739 |
1.163 |
|
Banking77 |
Is intent {intent label}? Think step-by-step: {CoT instructions} |
0.700 |
0.707 |
0.990 |
|
California Housing |
Location in Latitude & Longitude belongs to Southern California |
0.953 |
0.953 |
1.0 |
|
FEVER |
Is the claim supported by the text? |
0.782 |
0.853 |
0.917 |
In terms of scalability and costs, the architectural differences between BigQuery and AlloyDB lead to slightly different results for each system. At a high-level, proxy models move parts of the computation from specialized hardware used by LLM inference services to ordinary database workers. This results in a large reduction in costs and in query latency. In the online training case, employed by BigQuery, for a typical one million row query, proxy models consume about 400x less tokens, and the latency goes down by 30x-100x. In AlloyDB’s case the LLM costs of PREPARE, which are similar to BigQuery’s, can be amortized over arbitrarily many runs of the prepared statements that invoke proxy models.
The cost reduction (token consumed) and latency improvement (query speed up) for various table sizes.
Conclusion
AI functions calling LLMs are becoming commonplace in databases. Choosing the proper model for each AI function is an active area of academic research (e.g. BARGAIN). The key intuition is right-sizing models: Performant cheap models for “easy” problems, powerful reasoning models for the hard problems. Our work builds on the same principles, but while academic research has only used LLMs to navigate the performance spectrum, non-LLM proxy models push performance much further using ultra-lightweight and highly specialized models that deliver surprisingly good quality for many problems. Yet, we should not be surprised: After all, the proxy models feed on the rich semantics that foundation models bring to embeddings and they also feed on being trained by LLMs. As embedding models improve and extract increasingly richer and finer semantics from text and multimodal data (image, video), we suspect that non-linear classifiers will be useful to identify even more complex semantic patterns, further extend the applicability of proxy models (e.g. to AI joins also) and explore additional points on the performance/quality Pareto.
If you would like to learn more, our full paper dives into the differences between online vs. offline training, and compares the performance of different embedding models as well as various proxy models (linear regression, SVM, XGB).
You can try proxy models today in BigQuery (docs) and AlloyDB (docs), dramatically speed up the AI Functions of your SQL queries and reduce their token consumption.
We would like to thank Bo Dai, Yuchen Zhuang, Xingchen Wan, and Dale Schuurmans from Google Deepmind for developing the fundamental principles on proxy models in UQE and for their continuous guidance & support along our journey to bring them to Cloud customers. We also thank Yeounoh Chung and Fatma Özcan, our partners in the System Research Group, as well as the AlloyDB and BigQuery engineering teams.

