AI is fundamentally driven by data. It is used to train and tune models, enable agents to plan and reason, and fuel interactions with end users. However, it can also create risks, such as sensitive data leaks, unwanted data collection, and data misuse.
In the AI era, organizations need more than security controls that rely on manual tagging and simple keyword matching. Effective data protection now depends on understanding context.
To help you meet this challenge, Google Cloud’s Sensitive Data Protection (SDP) now uses advanced AI technology to power a new set of context classifiers (including medical and finance) and image object detectors (such as faces and passports). By understanding the context of data — even within images and rich documents — our enhanced rules engine can identify and mask sensitive information more effectively, helping to ensure that your AI agents access only the data they need.
Now generally available, these new SDP capabilities allow you to safely unlock the value of your data at every stage of the AI journey, from initial training and fine-tuning to real-time agent responses. By helping to ensure that sensitive identifiers like personally identifiable information (PII) are selectively removed, you can feed your models high-quality data without the associated risks.
Here are a few ways you can integrate these new SDP capabilities into your AI strategy.
AI tuning and data sanitization in Vertex AI
When you tune a model like Gemini with your own business data, you can introduce new risks hidden in your data. On Vertex AI, Sensitive Data Protection can help mitigate these risks by enabling managed data discovery. It continuously scans your organization or selected projects for sensitive markers, including those within unstructured image data.
For example, SDP discovery can find credit card numbers, faces, and photo ID cards using advanced optical character recognition (OCR) and object detection. When sensitive data is discovered, rather than discarding it and reducing the value of your training datasets, you can use SDP to generate redacted versions.
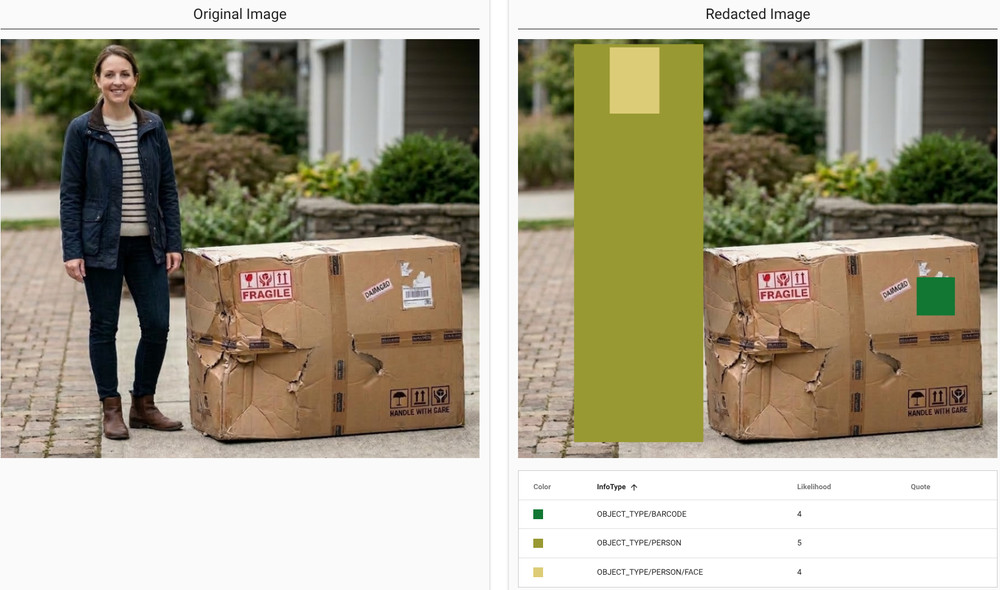
Consider the image below showing a damaged package next to a person. The system allows you to keep the image for training purposes while selectively obscuring the face or the entire person to ensure privacy.
Figure 1: Sensitive Data Protection redacts sensitive or unwanted objects in images from AI training data
You can check out the full list of object types that SDP can identify and redact from your AI training data.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Vertex AI’), (‘body’, <wagtail.rich_text.RichText object at 0x7f515871f4f0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Securing live AI interactions
After tuning and deploying your model, the challenge shifts to managing live interactions. As end users engage with your business agents, you should verify that the content of every conversation is appropriate and compliant before your model processes it.
Sensitive Data Protection can help solve this challenge by providing an enhanced understanding of natural language context. For example, if a user types, “My arm is broken and I can’t use the touchscreen,” the service detects a specific health context (DOCUMENT_TYPE/CONTEXT/HEALTH). Recognizing this as sensitive data, you can configure your system to redact the input — or block the conversation entirely.
Conversely, if the user says, “My wifi is broken,” the system recognizes the semantic difference. It understands this is a technical issue rather than a medical one, allowing the agent to proceed with troubleshooting the order.
You can explore the full list of context classification types to understand how Sensitive Data Protection can help verify the context of AI conversations.
Enhancing precision by combining context and rules
While context alone is important, complex scenarios often require combining it with traditional detectors. Standard approaches, like regular expressions (regex), are effective at finding patterns but often lack nuance, leading to false positives.
Sensitive Data Protection addresses this by combining context with pattern matching. By understanding the semantic category (such as “financial,” “medical,” “legal”), the system can boost or suppress findings to align with the actual risk.
For example, consider the phrase: “My order number is 75337 followed by 324323.” Here, the service detects a low-confidence GENERIC_ID. Since the context implies a standard tracking number, Sensitive Data Protection determines that no redaction is necessary.
Figure 2: Sensitive Data Protection preserves data based on context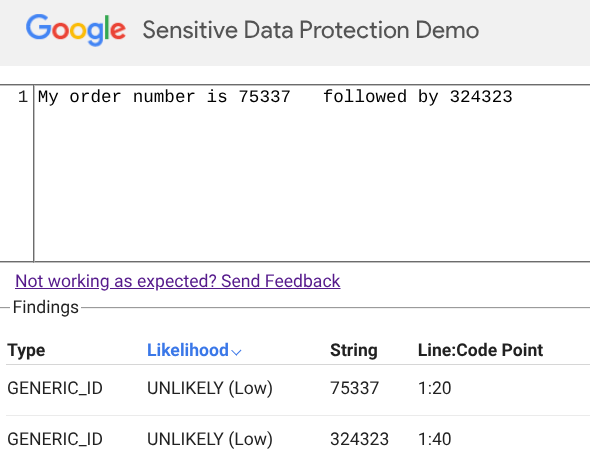
Now, consider a slight change: “My wallet number is 75337 followed by 324323.” The numbers are identical, but the word “wallet” triggers a strong DOCUMENT_TYPE/CONTEXT/FINANCE signal. This financial context boosts the confidence of the ID finding, validating it as sensitive data that requires redaction.
Figure 3: Sensitive Data Protection redacts sensitive data based on user context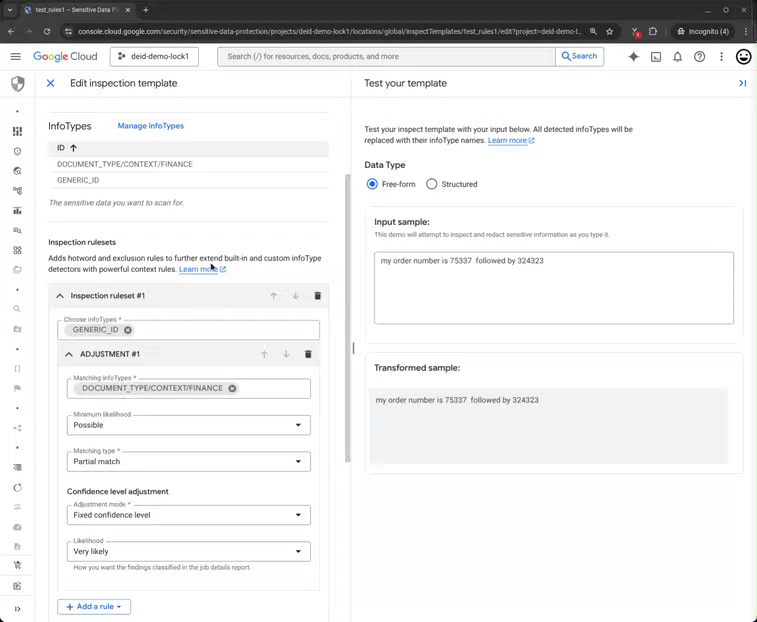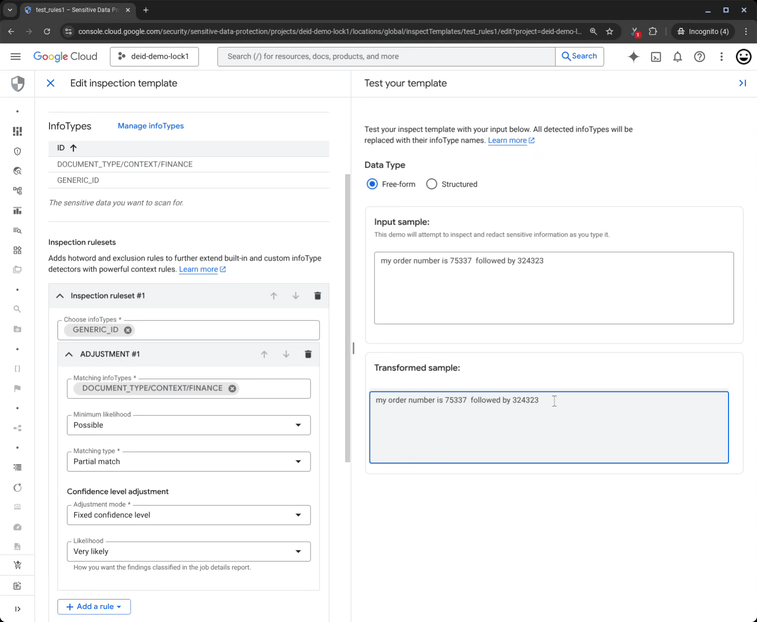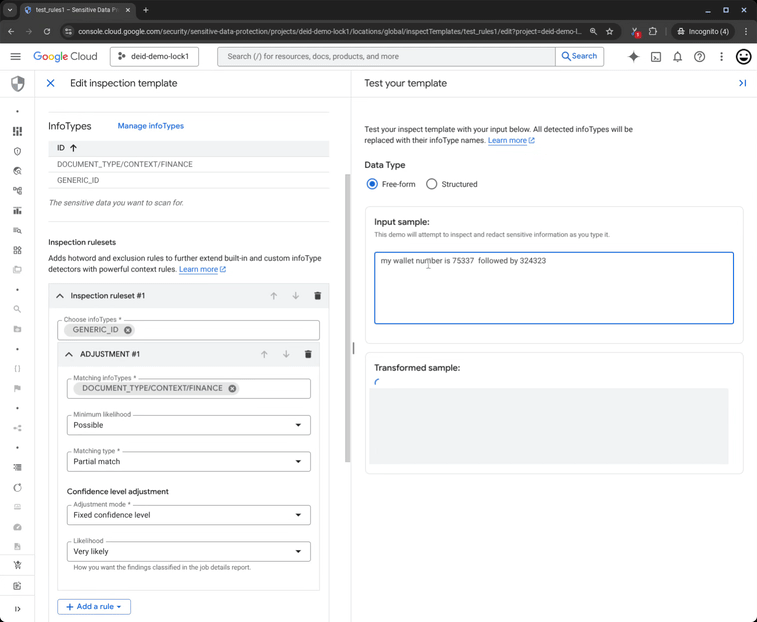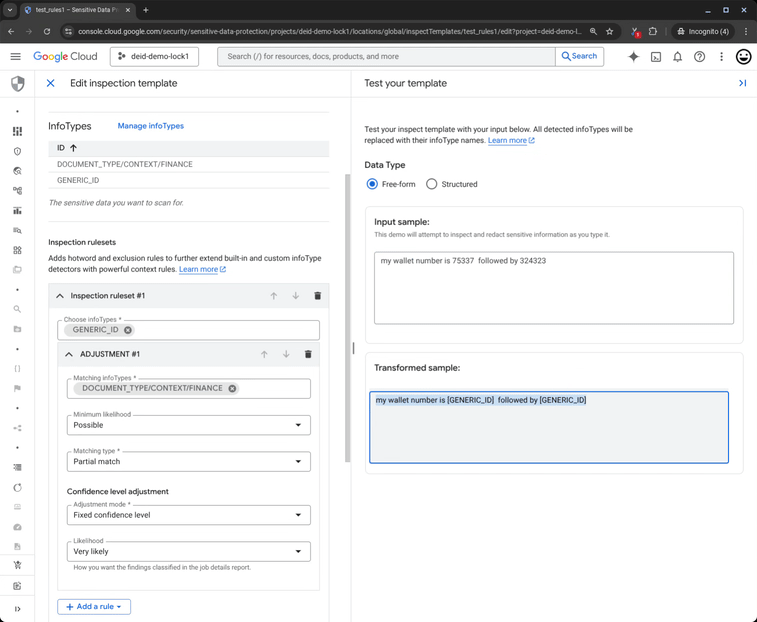
As AI agents become more autonomous and data formats more complex, developers need more than static rules to properly mitigate business risks. Google Cloud’s Sensitive Data Protection can help you embrace these technologies without compromising on security.
Getting Started
Sensitive Data Protection is the underlying discovery and inspection engine that powers data discovery and security guardrails in Model Armor, Security Command Center, and Contact Center as a Service. You can check out our new in-line configuration and testing interface directly in the Cloud Console, and learn how to configure SDP for use with Model Armor.

