To achieve Level 4 and Level 5 autonomous network operations (ANO), the telecommunications sector is increasingly turning to AI to build self-healing, self-optimizing networks capable of predictive maintenance.
However there is a significant roadblock: AI is only as good as the data fueling it. While the industry fixates on AI agents, large language models (LLMs), and AIOps, the underlying data remains messy and fragmented. You can’t build a valid AI model on broken data.
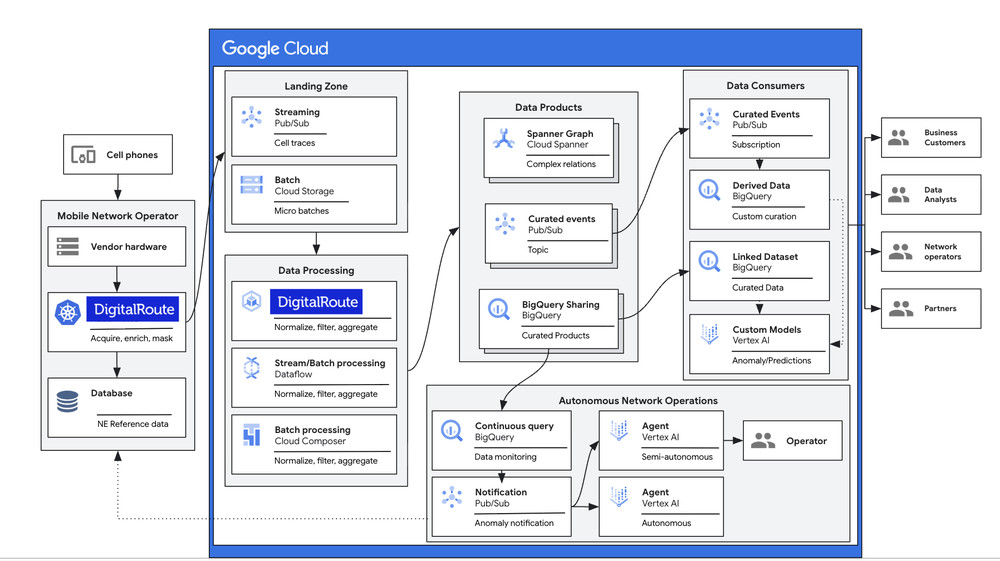
Today, we’re announcing a new collaboration with data usage and monetization platform provider DigitalRoute to solve one of the industry’s biggest hurdles: data readiness. We’re launching reusable data pipelines that transform raw, chaotic network noise into high-quality, “AI-ready” data, enabling the next generation of autonomous agents.
Moving from “data swamps” to digital twins
Before an AI agent can resolve a network anomaly, it must first understand the environment. In a modern telecom network, this is a massive engineering challenge for four reasons:
-
Format disparity: Network data arrives in dozens of proprietary formats (e.g., ASN.1, XML, CSV, Binary) that can vary by vendor and domain. AI can’t read these without a translator.
-
Volume and velocity: 5G networks generate billions of billing and event data records daily. Processing this in real time with ultra-low latency can crush legacy mediation systems.
-
Schema evolution: Every time a network function is upgraded or a new 5G feature is rolled out, the underlying data structure changes. This usually “breaks” traditional data systems.
-
Correlation complexity: A single customer session is often fragmented across multiple network elements. Without stitching these fragments together, AI lacks the context to understand the actual customer experience.
The result is a “data swamp” — massive amounts of unrefined information that AI models cannot use effectively.
The solution: A cloud-native architecture for data readiness
To address this, we’ve architected a solution with DigitalRoute that bridges legacy telecom protocols with cloud-native intelligence. By running DigitalRoute’s Usage Engine Private Edition on Google Kubernetes Engine (GKE), we’ve created a reusable pipeline that scales dynamically across edge and cloud locations.
This architecture provides three distinct advantages:
-
Normalization at the edge and core: We decode complex binary messages into a unified common data model and filter out irrelevant “noise” before it hits storage. This helps ensure downstream AI is decoupled from vendor-specific constraints while significantly reducing data egress costs.
-
The “dual-path” strategy: Once normalized, the data flows into two specialized environments:
-
For real-time operations: Data is pushed to Spanner to build a “network digital twin.” This allows AI agents to traverse network topology over time to perform a quick root cause analysis.
-
For long-term analytics: Historical data flows into BigQuery. Because BigQuery is serverless and scales instantly, it allows operators to analyze petabytes of network traffic without managing infrastructure, feeding ‘data products’ directly into Vertex AI for rapid model training.
Contextualized subscriber traces: Through our Network and Subscriber Trace Analysis (NSTA) solution, we align messages from different nodes based on timestamps and identifiers. This builds a coherent, chronological session flow, giving AI agents the end-to-end context of the subscriber’s journey.
This architecture ensures that whether an AI agent needs to react to a fiber cut in near real-time with Spanner or predict a capacity crunch next month with BigQuery and Vertex AI, it is always consuming consistent, high-quality data.

From data to outcome: Enabling autonomous agents
This partnership is about enabling production-grade AI use cases. By establishing these reusable pipelines, we provide the foundation for:
-
Rapid anomaly detection: Agents can detect subtle deviations in network performance because the baseline data is consistent and noise-free.
-
Automated root cause analysis: When a failure occurs, agents can correlate radio access network (RAN) issues with core trace data instantly to pinpoint the fix.
-
Predictive maintenance: Using historical data in BigQuery, operators can train Graph Neural Networks (GNN) to predict capacity bottlenecks days in advance.
Accelerate your autonomous network mission
Data readiness is the difference between a “science project” and a production-grade autonomous network. By standardizing the ingestion layer today, telecoms can build the essential foundation for the AI-driven networks of tomorrow.
Ready to start?
-
Contact Google Cloud Sales to schedule a Data Readiness Workshop and explore our reference architecture for Autonomous Network Operations.
- Reach out to DigitalRoute to learn how their Usage Engine on GKE can solve your specific format disparity and volume challenges.

